1 Speech Recognition System on Chip Overview
With the development of digital signal processing technology, the speech recognition system on chip has become a hot research topic. However, the contradiction between complex system and hardware requirements limits its application and promotion to some extent. In view of the above problems, this paper adopts the corresponding identification strategy [1], reasonably arranges the algorithm flow, and completes the on-chip implementation of high performance specific person and non-specific person identification system.
2 hardware platform
DSP selection requires a combination of operating speed, cost, power consumption, hardware resources, and program portability. This system adopts TMS320VC5507 fixed-point DSP produced by Texas Instruments (TI) as the core processor [2], and cooperates with PLL clock generator, JTEG standard test interface, asynchronous communication serial port, DMA controller, general-purpose input and output GPIO port and many more. Main on-chip peripherals such as channel buffer serial ports (McBSPs). The system hardware platform is shown in Figure 1.
VC5507 DSP chip adopts advanced multi-bus structure, including 64 K&TImes; 16 bit on-chip RAM and 64 KB ROM; on-chip shieldable ROM is solidified with bootloader (bootloader) and interrupt vector table; The overall speed of execution. Unlike the C54x family of DSPs, the VC5507DSP's memory space includes unified data, program space, and I/O space. The address space is up to 16 MB. The on-chip contains two arithmetic logic units (ALUs) at a maximum clock rate of 200. At MHz, the instruction cycle is up to 5 ns and the maximum speed is 400 MIPS.
The memory uses the M5M29GB/T320VP series Flash chip produced by Mitsubishi Corporation. The full-chip capacity is 2 MW, divided into 128 sectors. It is connected to the DSP through the external memory interface (EMIF) mode and read/write timing; it is powered by a single power supply of 2.7 V to 3.6 V. This series of Flash supports block programming operations [3], reading and writing speed is much faster, which is conducive to real-time improvement.
Fund Project:Project supported by the National Natural Science Foundation of China 60076083
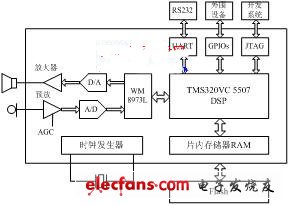
Figure 1 Speech recognition system hardware block diagram
The A/D and D/A converters use the WM8973L chip produced by Wolfson, UK. The chip supports 16-bit A/D, D/A conversion, programmable input and output gain control, and can be set by software to a variety of sampling frequencies from 8 to 96 KHz [4].
3 software structure
3.1 System Overview
The specific person identification system uses 12-dimensional MFCC parameters as the characteristic parameters of the recognition engine. The training and recognition are realized on-chip in real time. The system framework is shown in Figure 2(a). In the training phase, the feature parameters of each entry are extracted from the on-chip real-time into Flash as a template library. In the identification stage, after the feature parameters are extracted in real time and the endpoints are detected, the dynamic time warping (DTW) algorithm is used to match all the templates in the template library, and the template with the least distortion is selected as the recognition result. When the vocabulary changes, you only need to adjust the Flash storage mode, and the algorithm itself does not need to be changed.
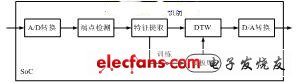
(a) Specific person system
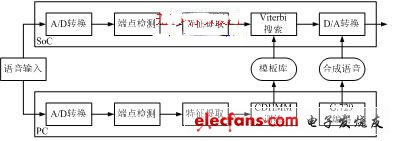
(b) Non-specific system
Figure 2 Identifying the system framework
The input feature vector of the non-specific person recognition system is 27-dimensional, including 12-dimensional MFCC, 12-dimensional MFCC first-order difference, first-order logarithmic energy, first-order differential energy, and second-order differential energy. The system uses the factor-based CDHMM model as the basic recognition framework and uses the Viterbi decoded frame synchronization search algorithm for recognition. The HMM model training is performed on the PC in advance, while the Viterbi search is implemented on the DSP chip in real time. The whole system is a two-layer structure, as shown in Figure 2(b).
The training phase mainly accomplishes the following tasks: Given an HMM model and a set of observation vectors, an iterative algorithm is used to adjust the model parameters so that the likelihood of the new model and the given set of observation vectors is maximized. Firstly, the initial model is used to estimate the posterior probability of the observation vector output from all possible state sequences of the hidden layer. Then, according to the estimation result of the previous step, the new HMM model is estimated by the maximum likelihood criterion, and the obtained parameters are used as the next iteration. . The identification phase uses Viterbi search, and the identified network includes information such as status numbers and status connections. In order to reduce the memory usage of the network search, a method of separately establishing a network for each term is adopted, so that the search process of each term can be performed independently in the memory [5].
Customized Solar Panel, 100watt solar panel,200watt solar panel, big solar panel, high efficiency high quality solar modules
different power customized and OEM logo customized solar panel
Customized solar panel data
solar cell type
mono crystalline half cut cell
power range
50watt to max 700watt
size and weight
different size and different weight if the power is different
solar panel type
monofacial or bifacial
solar panel color
sliver or black
Product details and pic



Customized Solar Panel,Noncrystalline Solar Panel Module,Cheap Price Pv Solar Module,Solar Photovoltaic Pv Panel
PLIER(Suzhou) Photovoltaic Technology Co., Ltd. , https://www.pliersolarpanel.com