The official guide to deploy Julia code directly to Google Cloud TPU and make the program run faster is here! The combination of Julia and TPU means fast and easy-to-express ML calculations! "
Julia is a programming language that gathers the expertise of many people. With the official release of Julia 1.0 in early August, the Julia language has become the new favorite of machine learning programming.
This programming language developed by the MIT CSAIL laboratory combines the speed of the C language, the flexibility of Ruby, the versatility of Python, and the advantages of various other languages. It is open source and easy to master.
With more and more users, the development tools, techniques, and tutorials surrounding Julia are becoming more abundant. Yesterday, Julia developers Keno Fischer and Elliot Saba published a new paper AutomaticFullCompilationof JuliaProgramsandMLModelstoCloudTPUs, introducing how to deploy Julia code directly to Google Cloud TPU to make the program run faster.
Jeff Dean recommended this paper on Twitter, commenting: "The combination of Julia and TPU means fast and easy-to-express ML calculations!"
Google's Cloud TPU is a very powerful new hardware architecture for machine learning workloads. In recent years, Cloud TPU has provided the impetus for many of Google's milestone machine learning achievements.
Google has now opened the provision of general-purpose TPUs on their cloud platform, and has recently opened up further to allow non-TensorFlow front-end use.
This paper describes the method and implementation of offloading appropriate parts of Julia program to TPU through this new API and Google XLA compiler.
This method can fully integrate the forward pass of the VGG19 model expressed as a Julia program into a single TPU executable file for offloading to the device. This method is also well integrated with the existing compiler-based automatic differentiation technology on Julia code, so we can also automatically obtain the reverse pass of VGG19 and similarly unload it to the TPU.
Using this compiler to locate the TPU, the VGG19 forward pass of 100 images can be evaluated in 0.23 seconds, which is a significant speedup compared to the 52.4 seconds required by the original model on the CPU. Their implementation requires less than 1,000 lines of Julia code, and there are no TPU-specific changes to the core Julia compiler or any other Julia packages.
Please read the original paper for specific methods and implementation details. The following mainly introduces from the review of the TPU hardware architecture, the workflow of the Julia compiler, the details of embedding XLA into Julia IR, and the results and discussions.

Google TPU and XLA compiler
In 2017, Google announced that they would provide their proprietary tensor processing unit (TPU) machine learning accelerator to the public through cloud services. Initially, the use of TPU was limited to applications written using Google's TensorFlow machine learning framework. Fortunately, in September 2018, Google opened up access to the TPU through the IR of the lower-level XLA (Accelerated Linear Algebra) compiler. The IR is universal and is an optimizing compiler used to express arbitrary calculations of linear algebra primitives, so it provides a good foundation for TPU targets for non-Tensorflow users and non-machine learning workloads.
XLA (Accelerated Linear Algebra) is a part of Google's open source compiler project. It has a rich input IR, used to specify multi-linear algebra calculations, and provides back-end code generation functions for CPU, GPU and TPU. XLA's input IR (called HLO advanced optimization IR) operates on arbitrary-dimensional arrays of basic data types or tuples (but no tuple arrays). HLO operations include basic arithmetic operations, special functions, generalized linear algebra operations, advanced array operations, and primitives for distributed computing. XLA can perform semantic simplification of input programs and memory scheduling of the entire program in order to effectively use and reuse available memory (this is a very important consideration for large machine learning models).
Each HLO operation has two operands:
Static operand, its value must be available at compile time and the operation is configured.
The dynamic operand is composed of the above tensor.
This paper introduces the preliminary work of using this interface to compile conventional Julia code with TPU. This method does not rely on tracking, but uses Julia's static analysis and compilation functions to compile the complete program, including any control flow of the device. In particular, our method allows users to make full use of the full expressiveness of the Julia language when writing models. It can compile a complete machine learning model written using the Flux machine learning framework, and integrate forward and backward model transfer and training loops into a single executable. Execute the file and unload it to TPU.
How the Julia compiler works
In order to understand how to compile Julia code into XLA code, it is useful to understand how a regular Julia compiler works. Julia is a very dynamic language semantically. However, in the standard configuration, Julia's final back-end compiler is LLVM (Lattner & Adve, 2004), which is a static compiler back-end.
The Julia compiler needs to link the dynamic semantics of the language with the static semantics represented by LLVM. In order to understand this process, we will study four aspects of the Julia system: dynamic semantics, static compiler internal function embedding, inter-procedural type inference, and static subgraph extraction. In addition, we will also study the interaction of these features with macros and generated functions, which will be related to the XLA compiler.
How to embed XLA into Julia IR
XLA embed
To compile to XLA instead of LLVM, we applied the strategy outlined in the previous section. In fact, we can reuse most of the compiler itself (especially all type inference and all mid-level optimization passes).
Let us first define dynamic semantics and static embedding.
Tensor representation
Because of its tradition as a language for teaching and research in linear algebra, Julia has a very rich abstract hierarchy of arrays. Julia's standard library arrays are mutable and parameterized in type and dimension. In addition, the StaticArrays.jl (Ferris & Contributors, 2018) package provides immutable arrays that are parameterized on element types and shapes. Therefore, the concept of shaped N-dimensional immutable tensors is not unfamiliar to Julia code, and most existing general-purpose codes can handle it without problems.
Therefore, we embed XLA values ​​by defining a runtime structure.

Listing 1: Definition of XRTArray3.
Operation representation
Separate static and dynamic operands
HLO operands are divided into static and dynamic operands. Suppose we have an example XLA operation'Foo' that takes one static operand (for example, an integer) and two dynamic operands. This embedding looks like this:

In this example, the "execute" function implements the dynamic semantics of running operations on the remote device. The function (hlo::HloFoo)(...) syntax means calling operator overloading. Therefore, this means that the call to HloFoo(1) will construct and return a callabale object. When called on two XRTArrays, it will use the static operand '1' to remotely perform the'Foo' HLO operation, and correspond to two The dynamic operand of the array. This separation is not absolutely necessary, but it does have useful features embedded in Julia IR, which is easy to understand:
In the example in Listing 2, we spliced ​​HLO operands (including static operands) into the AST. This produces a very simple XLA mapping (traverse each sentence, get the static operand from the splicing instruction specification, get the dynamic shape from the type inference, and generate the corresponding XLA code).
Of course, we usually do not splice these instructions manually, but the manual splicing example illustrates why it is useful to separate the static operands and illustrates the conditions for successful offload to XLA.
If after all relevant Julia level optimizations, IR can be completely uninstalled:
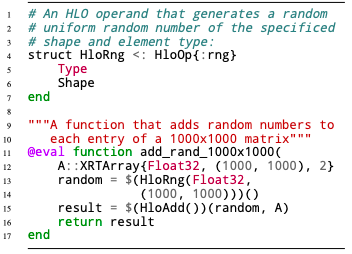
Listing 2: Manually built XLA embedding
IR that meets these conditions can be simply converted to XLA IR.
result
The method described in this article relies heavily on the Julia mid-end compiler to determine sufficiently accurate information to amortize any startup overhead in a sufficiently large sub-area of ​​the program.
In this section, we prove that the Julia compiler is indeed accurate enough to make this method suitable for actual programs.
VGG19 forward pass
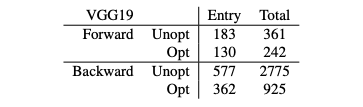
Figure 1: After compiling to XLA, the summary of XLA instructions generated by the forward pass and backwards pass of Metalhead.jl VGG19.
This shows the unoptimized (after Julia front-end) and optimized counts (after the XLA optimized pipeline similar to the CPU back-end used, but without HLO integration).
VGG19 backward pass
In order to obtain the backwards pass, we use the AD framework based on the Zygote.jl compiler (Innes, 2018). Zygote operates on Julia code, and its output is also a Julia function (suitable for reintroducing Zygote to obtain higher-order derivatives, and also suitable for compiling to TPU).
Examples are as follows:

in conclusion
In this paper, we discussed how to compile Julia code into XLA IR to achieve offloading to TPU devices. The implementation described here re-uses important parts of the existing Julia compiler, so all the code is less than 1000 lines, but it is still able to compile the forward and backward passes of the model (and its integration, including the training loop) into a single XLA kernel, such as VGG19.
We also demonstrated how Julia's multiple scheduling semantics can help in this conversion specification. This work shows that not only can multiple ML models written in Julia be compiled to the TPU, but also more general non-ML Julia codes can be written (as long as these codes are also controlled by linear algebra operations). We hope this can accelerate the exploration of non-ML problem areas, and TPU may be useful in these areas.
Company Introduction: Naturehike Products Co., Ltd. is a leading outdoor gear and equipment manufacturer based in China. The company is committed to providing high-quality and affordable outdoor gear to customers around the world. With a focus on innovation and design, Naturehike Products Co., Ltd. has become a trusted brand among outdoor enthusiasts. The company's products are designed to withstand the rigors of outdoor activities and are tested in extreme conditions to ensure their durability and performance. Naturehike Products Co., Ltd. is dedicated to promoting the outdoor lifestyle and helping people connect with nature.Company Introduction: Naturehike Products Co., Ltd. is a leading outdoor gear and equipment manufacturer based in China. The company is committed to providing high-quality and affordable outdoor gear to customers around the world. With a focus on innovation and design, Naturehike Products Co., Ltd. has become a trusted brand among outdoor enthusiasts. The company's products are designed to withstand the rigors of outdoor activities and are tested in extreme conditions to ensure their durability and performance. Naturehike Products Co., Ltd. is dedicated to promoting the outdoor lifestyle and helping people connect with nature.Company Introduction: Naturehike Products Co., Ltd. is a leading outdoor gear and equipment manufacturer based in China. The company is committed to providing high-quality and affordable outdoor gear to customers around the world. With a focus on innovation and design, Naturehike Products Co., Ltd. has become a trusted brand among outdoor enthusiasts. The company's products are designed to withstand the rigors of outdoor activities and are tested in extreme conditions to ensure their durability and performance. Naturehike Products Co., Ltd. is dedicated to promoting the outdoor lifestyle and helping people connect with nature.
Enzyme Cream,Whitening Slimming Enzyme Cream ,Meal Replacement Diet Enzyme Cream ,Conditioning After Surgery Enzyme Cream
YIWU BEAUTYPLUS ART NAIL CO., LTD. , https://www.cn-gangdao.com