Editor's note: The authors of this article Mihir Garimella and Prathik Naidu are sophomore students at Stanford University. In this article, they summarized the technology needed for 3D scene perception and the direction of future development.
Suppose you want to build a self-driving car, it needs to understand the surrounding situation. What method would you use to make the car perceive pedestrians, bicycles and other obstacles around it? You may think of using a camera, but it may not be very efficient: you need to take a picture of a 3D environment and then compress it into a 2D image. After that, the model will reconstruct the 3D image information you need (for example, the distance between the vehicle and the pedestrian in front). The process of compressing 3D images will lose a lot of important information, but it is very difficult to piece together this information later, even the most advanced algorithms will make mistakes.
So, ideally, you should be able to use 3D data to optimize the 2D landscape, and you can directly use sensors to locate obstacles in front of you, instead of using 2D images to estimate the distance between pedestrians or other vehicles and you. But at this time there will be a new question: how can we identify the target object in the 3D data? For example, pedestrians, bicycles, cars, etc. Traditional CNN will directly recognize different objects in 2D images, and then adjust them in 3D. The problem of 3D perception has been studied for a long time, and this article is a general review of this work.
In particular, we will focus on the recent deep learning technologies that can realize the classification and semantic segmentation of 3D objects. We will start with the common methods of capturing and representing 3D data, and then we will show three basic deep learning methods for representing 3D data. Finally, we will think about new directions for future research.
How to capture and represent 3D data?
Obviously, we need computer vision methods that can directly operate on 3D data, but there are three major problems: perception, representation, and understanding of 3D data.
Perceive
The process of capturing 3D data is very complicated. Although 2D cameras are cheap and widely used, special hardware equipment is required for 3D perception.
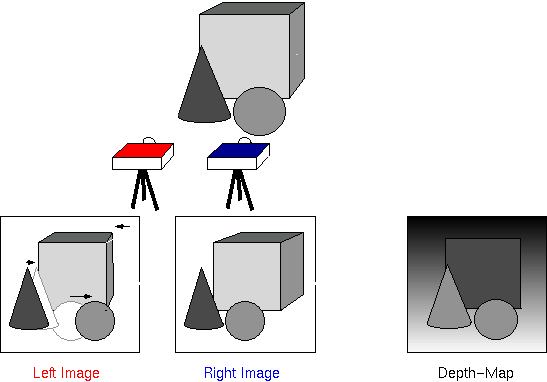
Stereo vision uses multiple cameras to shoot in different directions to calculate depth information
1. Place the camera in two or more positions, capture the target image in different scenes, and then match the corresponding pixels to calculate the difference in the position of each pixel in different photos. This is also the way humans see the world-our eyes capture two different pictures, and then the brain determines the 3D scene according to the different angles of the left and right eyes. Stereo vision requires only a few ordinary cameras, and the equipment is very simple, so it attracts many users. However, this method does not perform so well when performing precise measurements or calculating speed, because matching relative points between images with visual details not only requires a lot of computing power, but also causes many errors.

RGB-D camera can output an image with four channels, which contains color information and pixel depth
2. RGB-D is a special camera that can not only capture depth information (D) but also image color (RGB). And it can capture the same color image as a 2D camera. Most RGB-D sensors work through "structured light" or "time of flight". You may have heard that Microsoft’s Kinect or iPhone X’s Face ID sensor includes RGB-D cameras. They are powerful because of their small size, low cost, and high speed. However, RGB-D cameras often have many holes in the depth output because of obstacles in the front background or failures in pattern recognition.

LIDAR uses several lasers to directly perceive the geometric structure of the environment
3. LIDAR emits high-speed laser pulses to target objects and calculates the time for them to return to the sensor. It is similar to the "time-of-flight" technology of RGB-D cameras, but the detection range of LIDAR can be longer, can capture more points, and is not easily affected. Interference from other light sources. Most self-driving cars currently use these types of sensors because of their high accuracy, wide range and stability. But LIDAR is usually large and expensive, and many companies are developing cheaper LIDAR systems.
3D representation
After obtaining the data, you need to use a suitable method to express it. There are four mainstream representation methods:
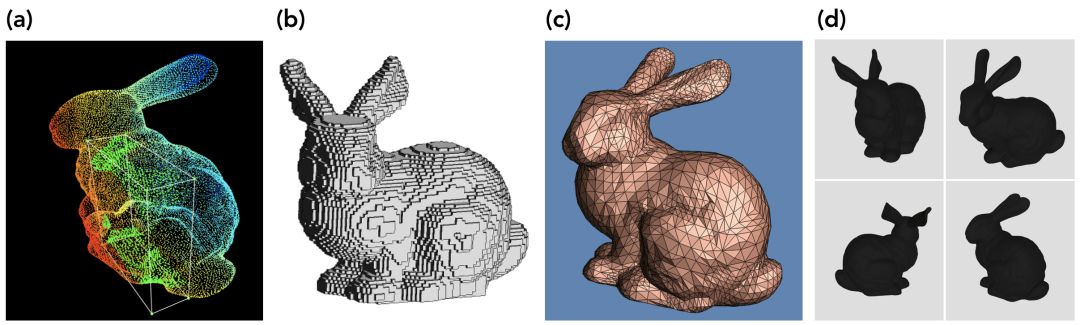
From left to right: point cloud; voxel mesh; polygon mesh; multi-angle representation
1. A point cloud is a collection of points in a 3D space. Each point is represented by a coordinate (xyz) and has other characteristics (such as RGB color). They are all the original forms of the captured LIDAR data. Usually, the stereo and RGB-D data will be converted into point cloud form before proceeding to the next step of processing.
2. The Voxel grid is evolved from a point cloud. Voxel is like a pixel in 3D. We can imagine a voxel grid as a quantized, fixed-size point cloud. Although the point cloud can have a wireless number of point and floating-point pixel coordinates at any location in space, the voxel grid is a 3D grid in which each voxel has a fixed size and independent coordinates.
3. Polygonal mesh is a group of multiple deformations with common vertices to form an approximate geometrical surface. Imagine a point cloud as a collection of 3D points collected from a continuous collection of surfaces. The purpose of a polygonal grid is to represent these surfaces in a way that is easy to render. Although originally created for computer graphics, polygon meshes can also be used for 3D vision. There are many ways to obtain a polygon mesh from a point cloud. You can refer to Poisson surface reconstruction by Kazhdan et al. (Address: http://hhoppe.com/poissonrecon.pdf "Poisson surface reconstruction").
4. Multi-angle representation is a collection of 2D images captured from multiple angles and rendered polygonal meshes. The difference between only capturing different images from multiple cameras and creating a representation of multiple angles is that multiple angles require building a complete 3D model and rendering from multiple arbitrary angles to fully convey the underlying geometric image. Unlike the other three representations above, multi-angle representation usually transforms 3D data into a simpler form for processing visualization.
understanding
Now that you have converted the 3D data into a readable form, you need to create a computer vision pipeline to understand it. The problem here is that extending traditional deep learning techniques to 3D data can be tricky.
Learn through multi-angle input
Multi-angle representation is the easiest way to apply 2D deep learning to 3D. Converting 3D perception problems into 2D perception is a smart way, but it still requires you to reason about the 3D geometry of the target object. The early deep learning research using this method is Su et al.'s multi-angle CNN, which is a brief but efficient network structure that can learn feature descriptions from multiple 2D images. Using this method, the result is better than using 2D images alone. Input individual images into the trained VGG network, extract the most important features, pool these activation maps, and then pass the information to other convolutional layers for feature learning.
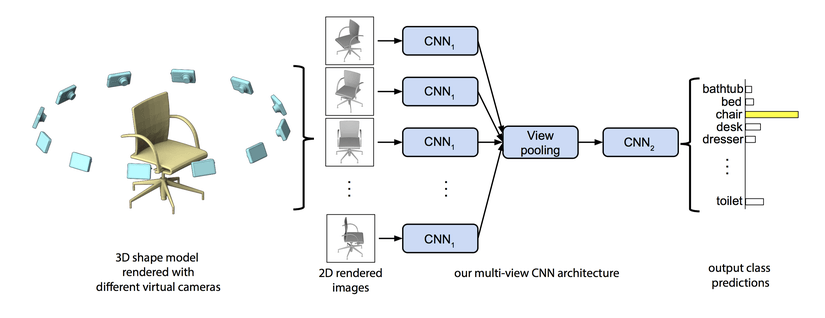
However, multi-angle image representation has some limitations. The main problem is that we are not really learning 3D, and a certain amount of 2D angle images cannot really estimate the 3D structure. Therefore, some tasks similar to semantic segmentation, especially complex targets and scenes, will be limited by feature information. In addition, this form of 3D data visualization is not scalable and will be limited in computation.
Express learning by volume
Through voxel grid learning, the main shortcomings of multi-angle representation are solved. The voxel grid fills the gap between 2D and 3D representation. Maturana and Scherer's VoxNet (address: https://) is the first method of deep learning to achieve better results in image classification.
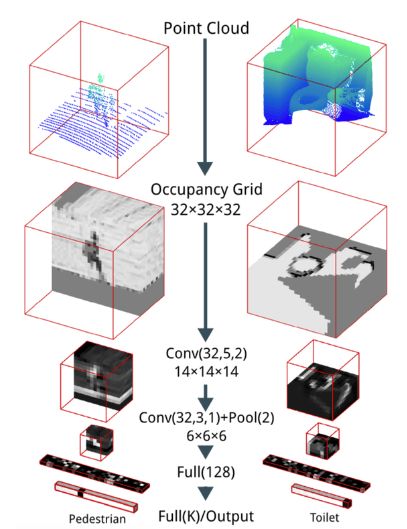
VoxNet structure
The structure of VoxNet is very simple, including two convolutional layers, a maximum pooling layer and two fully connected layers for calculating the output score vector. The network structure is simpler and has fewer parameters, but it is randomly searched from hundreds of CNN architectures.
Learn with point cloud
PointNet
Due to the many limitations of the voxel-based method, some recent studies have begun to directly deal with the original point cloud. The PointNet (address: arxiv.org/pdf/1612.00593.pdf) proposed by Qi et al. in 2016 is the first method to deal with this irregular 3D data. However, as the author of the paper said, point clouds are just 3D representations combined with xyz coordinates. In addition, the network should remain stable to changes in the point cloud, such as rotation, flipping, zooming, and so on.
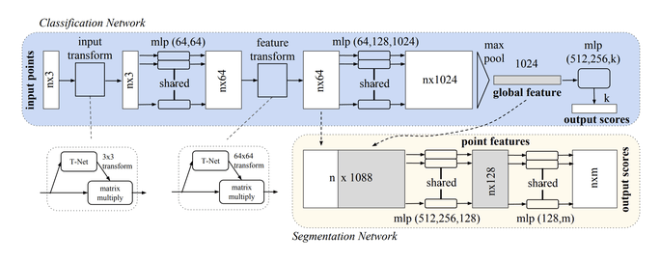
PointNet structure
PointNet++
Although PointNet can achieve better results, one of its important flaws is that the structure cannot capture the local structure within the neighboring points. In order to solve this problem, Qi et al. proposed PointNet++ (Address: arxiv.org/pdf/1706.02413.pdf) in 2017. It is an upgraded version of PointNet. The main principle behind it is a hierarchical feature learning layer. The main work is There are three steps in the process. First, it will sample the points and use them as the center of the local area, then group them according to the distance from the neighboring points to the center point in these areas, and then use mini-PointNet to encode the features of the area.
New directions for future research
At present, the processing of 3D data is mainly focused on point cloud representation, in addition to some other results. In 2018, Dynamic Graph CNNs proposed by Wang et al. used graph-based deep learning methods to improve feature extraction in point clouds.
On the other hand, some researchers have designed new methods to deal with point clouds. The SPLATNet architecture of Su et al. is a typical example. The author designed a new architecture and convolution operator, which can operate directly on the point cloud. Its core idea is to transform the concept of "receptive domain" into an irregular point cloud, so that spatial information can be seen even in a sparse space.
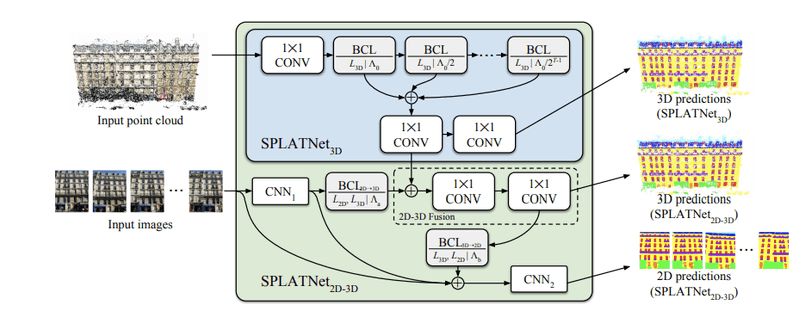
SPLATNet architecture
The third type of promising research line of defense is to expand the infrastructure and build a more detailed network for 3D target detection. In 2017, Frustum Pointns of Qi et al. proposed a new method that fused RGB images with point clouds to improve the efficiency of model positioning in 3D scenes.
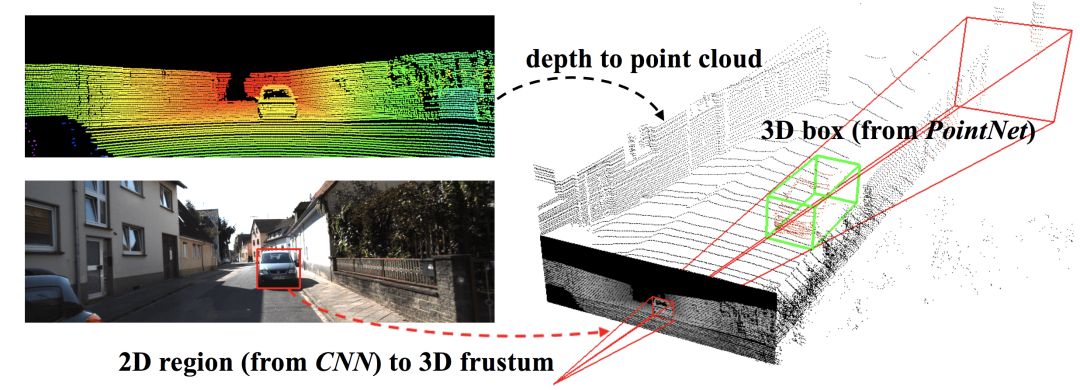
Conclusion
In the past five years, 3D deep learning methods have developed from multiple angles to 3D data representation of point clouds. Various processing methods have emerged one after another. These research results are very promising because they can truly represent the real world in 3D.
However, these advances are only the beginning. The current work not only focuses on how to improve the accuracy and performance of the algorithms, but also to ensure their stability and scalability. Although most of the current research comes from the needs of autonomous driving, the method of directly operating on the point cloud can play a great role in 3D medical imaging, VR, and indoor maps.
If you want to know more about the products in FLOW Vape, please click the product details to view parameters, models, pictures, prices and other information about FLOW Vape. And deliver to the destination just cost 7-15davs.We are a legal e-cigarette trader in China. We can provide you with FLOW Disposable Vape. Here you can find the related products in FLOW Vape, we are professional manufacturer of FLOW Vape. We focused on international export product development, production and sales. We have improved quality control processes of FLOW Vape to ensure each export qualified product.
Sufficient supply and favorable price, If you need to pick up goods wholesale, don't miss us.


Folw Vape,Folw Disposable Electronic Cigarette,FLOW Disposable Vape ,Flow Cigarette Cartridge Kit,FLOW Vape Kit
TSVAPE Wholesale/OEM/ODM , https://www.tsecigarette.com