
▌ Introduction
It is recommended as a technical means to solve information overload and tap the potential needs of users. It plays an important role in the business life-rich e-commerce platform of Meinuan. In the US group app, important business scenarios such as “Guess what you likeâ€, operation area, hotel travel recommendation, etc. are recommended for use.
Figure 1 US group home page "guess you like" scene
At present, the deep learning model has made major breakthroughs in many fields with its powerful expressive ability and flexible network structure. The Meituan platform has a large number of user and merchant data, as well as rich product usage scenarios, and also provides for deep learning applications. Necessary conditions. This paper will mainly introduce the application and exploration of the deep learning model in the recommended sorting scenario of the Meituan platform.
Application and exploration of ▌ deep learning model
In the US Mission recommendation scenario, millions of users are active every day. These users interact with the product to generate a large amount of real behavior data, and can provide one billion effective training samples every day. In order to deal with large-scale training samples and improve training efficiency, we developed a distributed training DNN model based on PS-Lite, and based on the framework, many optimization experiments were carried out, and significant improvement in the sorting scene was achieved.
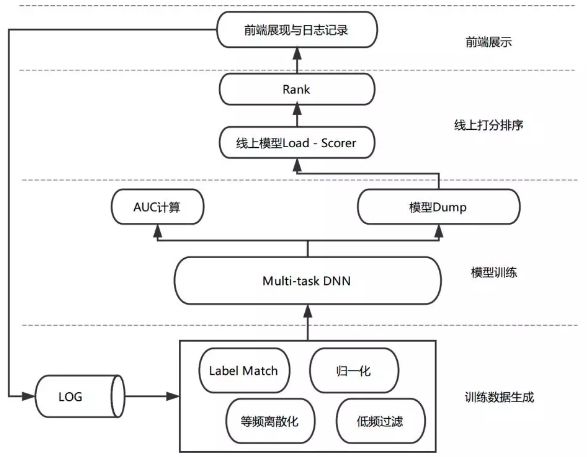
Figure 2 Model sorting flow chart
As shown in the figure above, the model sorting process includes stages such as log collection, training data generation, model training, and online scoring. When the recommendation system recommends the user browsing the recommended scene, the current product characteristics, user status, and context information are recorded, and the recommended user behavior feedback is collected. The final training data is generated after the tag matching and feature processing flow. We use the PS-Lite framework offline to perform distributed training on the Multi-task DNN model, select the better-performing models through off-line evaluation indicators and load them onto the line for online sorting services.
The following highlights our optimization and experimentation in feature processing and model structure.
Feature processing
The US Mission "Guess You Like" scene has access to a variety of businesses including food, hotels, travel, takeaway, homestay, transportation, etc. These businesses have rich connotations and characteristics, while the supply, demand and weather, time of each business, The geographical location and other conditions interweave constitute the unique diversity and complexity of the O2O life service scene, which puts higher requirements on how to organize the sorting results more efficiently. Constructing more comprehensive features and using samples more accurately and efficiently has always been the focus of our optimization.
Feature type
User characteristics: user age, gender, marriage, children, etc.
Item features: price, discount, category and brand related characteristics, short-term and long-term statistical features, etc.
Context features: weather, time, location, temperature, etc.
User behavior: the user clicks on the Item sequence, orders the Item sequence, etc.
In addition to the several types of features listed above, we also cross-examine some of the features based on the knowledge accumulation in the O2O field, and further deal with the features for learning effects. The specific sample and feature processing flow is as follows:
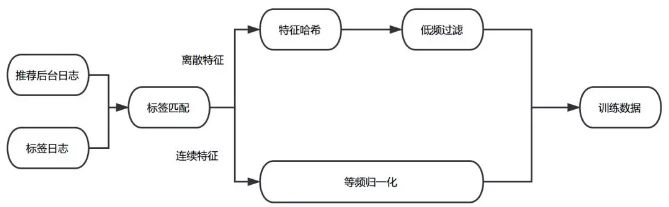
Figure 3 training data processing flow
Tag matching
It is recommended that the background log records the User feature, Item feature, and Context feature of the current sample. The Label log captures the user's behavior feedback for the recommended item. We stitched the two pieces of data together by a unique ID to generate the original training log.
Equal frequency normalization
Through the analysis of the training data, we find that the distribution of values ​​of different dimensional features and the difference of eigenvalues ​​in the same dimension are very large. For example, the data of features such as distance and price obey the long tail distribution, which means that the eigenvalues ​​of most samples are relatively small, and the eigenvalues ​​of a small number of samples are very large. Conventional normalization methods (such as min-max, z-score) only translate and stretch the distribution of the data. Finally, the distribution of features is still a long tail distribution, which results in the eigenvalues ​​of most samples being concentrated. In a very small range of values, the discrimination of sample features is reduced; at the same time, a small number of large-value features may cause fluctuations during training and slow down the convergence rate. In addition, the eigenvalues ​​can be logarithmically transformed, but due to the different distribution of features between different dimensions, the eigenvalue processing method does not necessarily apply to other dimension features.
In practice, we refer to Google's Wide & Deep Model [6] for the treatment of continuous features, normalized according to the position of the feature values ​​in the cumulative distribution function. The feature is to be equally frequency-divided to ensure that the sample size in each bucket is basically equal, assuming that a total of n buckets are divided, and the feature xi belongs to the second bi(bi ∈ {0, ..., n - 1}) buckets. Then, the feature xi will eventually be normalized to bi/n. This method ensures that features of different distributions can be mapped to an approximately uniform distribution, thereby ensuring the discrimination of the features between samples and the stability of the values.
Low frequency filtering
Excessively sparsely discrete features can cause over-fitting problems during training and increase the number of parameters stored. In order to avoid this problem, we perform low-frequency filtering on discrete features and discard features that are less than the frequency threshold.
After the above feature extraction, label matching, and feature processing, we assign the corresponding domain to the feature, and hash the discrete feature, and finally generate the data in LIBFFM format as the training sample of Multi-task DNN. The following is an attempt to optimize the model for business goals.
Model optimization and experiment
In terms of models, we draw on the successful experience of the industry and optimize the model structure for the recommended scenarios based on the MLP model. In deep learning, many methods and mechanisms are universal. For example, the Attention mechanism has achieved significant improvement in machine translation and image annotation. However, not all specific model structures can be directly migrated. This requires a combination. In actual business problems, the introduced model network structure is adjusted in a targeted manner to improve the effect of the model in specific scenarios.
Multi-task DNN
The optimization goal on the recommended scenario should take into account the user's click rate and order rate. In the past, when we used XGBoost for single-target training, we balanced the click rate and the order rate by taking the sample of the click and the sample of the order as positive samples and upsampling or weighting the samples of the order. However, the weighting method of this sample also has some disadvantages. For example, the cost of adjusting the order weight or sampling rate is high, and each adjustment needs to be retrained, and it is difficult for the model to express the two parameters with the same set of parameters. Mixed sample distribution. In response to the above problems, we introduced Multi-task training using DNN's flexible network structure.
According to the business objectives, we split the click rate and the order rate to form two independent training targets, and establish their respective Loss Function as the supervision and guidance for the model training. The first few layers of the DNN network act as a shared layer, and the click task and the order task share their expressions, and the parameters are updated in the BP phase according to the gradients calculated by the two tasks. The network splits at the last fully connected layer, learning the parameters corresponding to Loss separately, so as to better focus on fitting the distribution of the respective Labels.
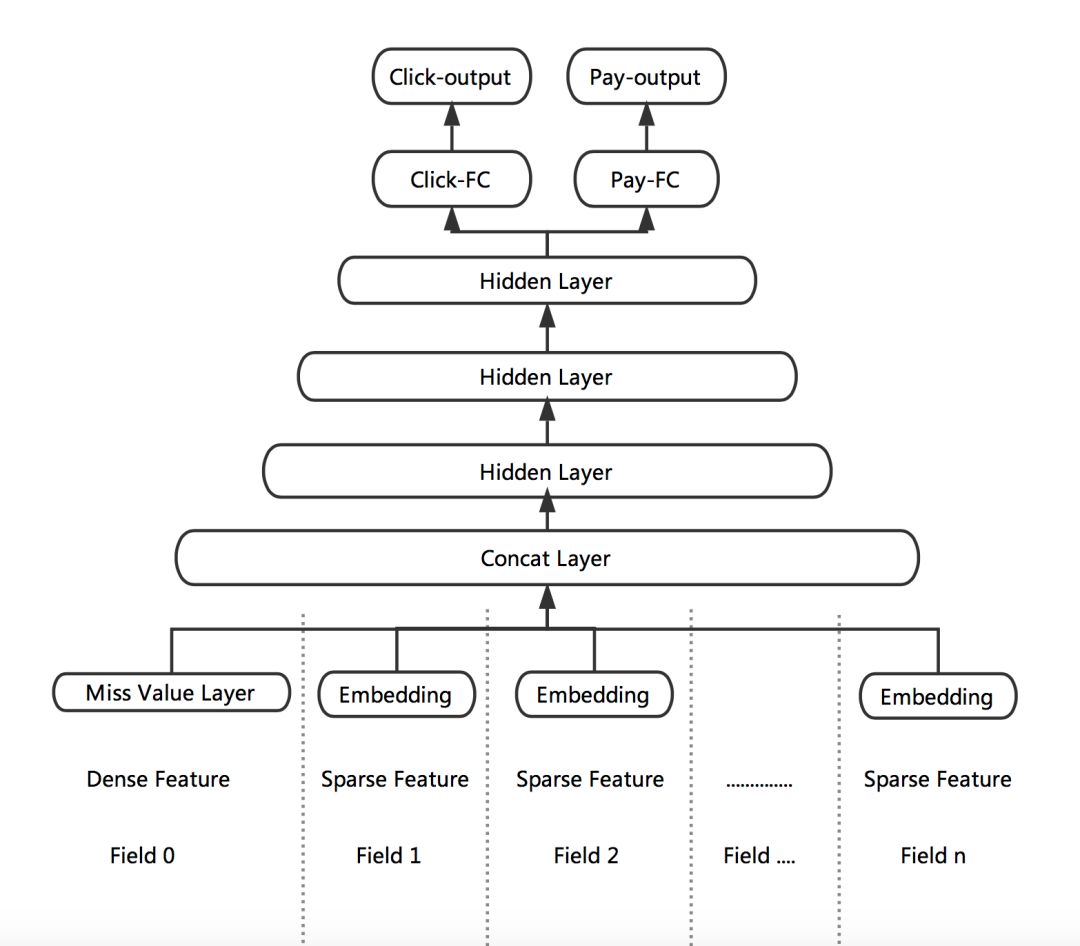
Figure 4 Click and place multi-target learning
The network structure of the Multi-task DNN is shown in the figure above. For online forecasting, we make a linear blend of Click-output and Pay-output.
Based on this structure, we further optimized the data distribution characteristics and business objectives: we propose the Missing Value Layer for the ubiquitous feature loss to fit the online data distribution in a more reasonable way; The physical meaning of the task is related. We propose KL-divergence Bound to mitigate the influence of a single target. Below we will give a detailed introduction to these two tasks.
Missing Value Layer
It is often difficult to avoid missing values ​​in some continuous features in the training samples. Better handling of missing values ​​will help the convergence and final effects of the training. The way to treat continuous feature missing values ​​is usually to take a zero value or take the average of the dimension features. Taking a zero value causes the corresponding weight to fail to update and the convergence speed to slow down. The average value is also slightly arbitrary. After all, the meaning of different feature missing may be different. Some non-neural network models can deal with missing values ​​reasonably. For example, XGBoost will adaptively judge whether the missing samples of the feature are classified into the left subtree or the right subtree through the calculation process of Loss. Inspired by this, we hope that neural networks can also adaptively handle missing values ​​in a learning way, rather than artificially setting default values. Therefore, the following Layer is designed to adaptively learn the weight of missing values:
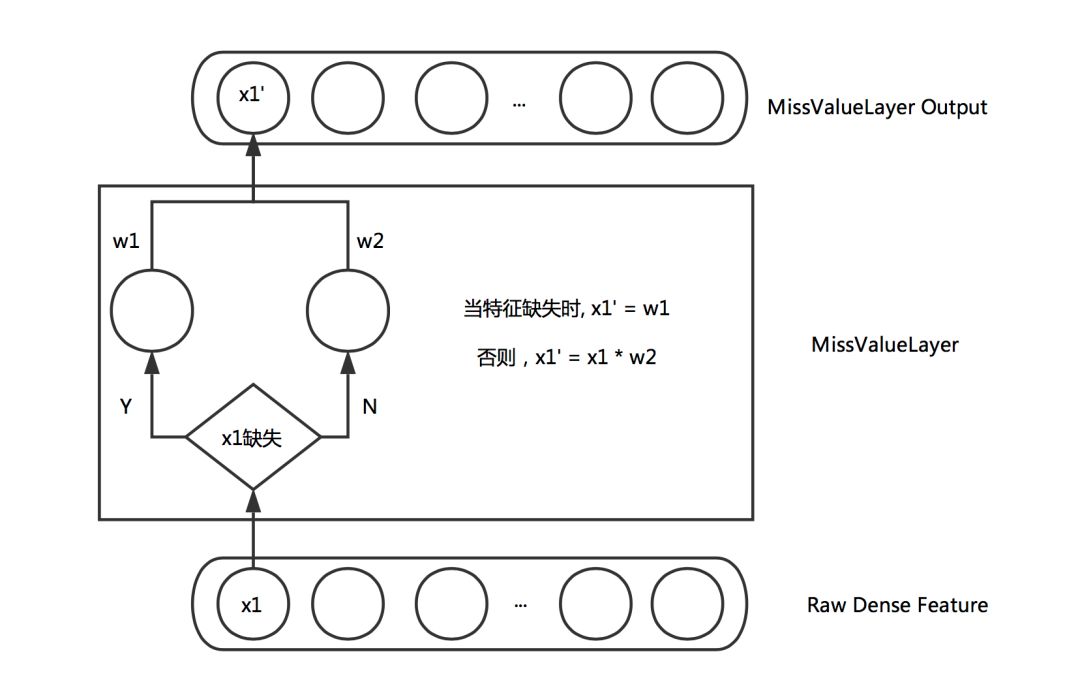
Figure 5 Miss Value Layer
Through the above Layer, the missing features can adaptively learn a reasonable value according to the distribution of the corresponding features.
Through off-line research, the method of adaptive learning feature missing values ​​is far superior to the method of taking zero value and taking the mean value for improving the training effect of the model. The change of the model offline AUC with the number of training rounds is as follows:
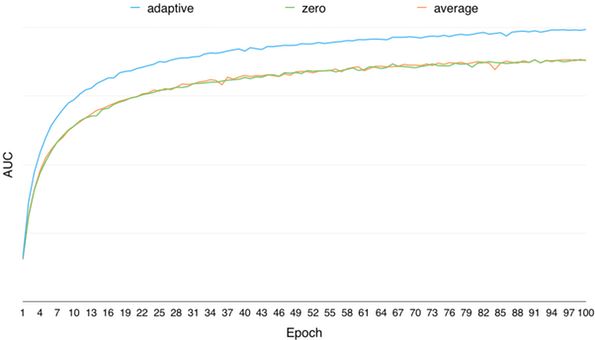
Figure 6 Comparison of adaptive learning feature missing values ​​and taking 0 value and mean value
The relative value of AUC is increased as shown in the following table:
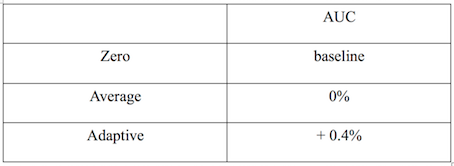
Figure 7: Adaptive learning feature missing value AUC relative value increase
KL-divergence Bound
We also consider that different labels will have different Noise. If the related Labels can be related by physical meaning, the robustness of model learning can be improved to a certain extent, and the influence of the individual label's Noise on training can be reduced. For example, the MTL can simultaneously learn the sample click rate, order rate and conversion rate (order/click), and the three meet the meaning of p (click) * p (transformation) = p (order). So we added a Bound of KL divergence, making the predicted p (click) * p (transformation) closer to p (order). However, since the KL divergence is asymmetrical, that is, KL(p||q) != KL(q||p), when it is actually used, the optimization is KL(p||q) + KL(q||p ).
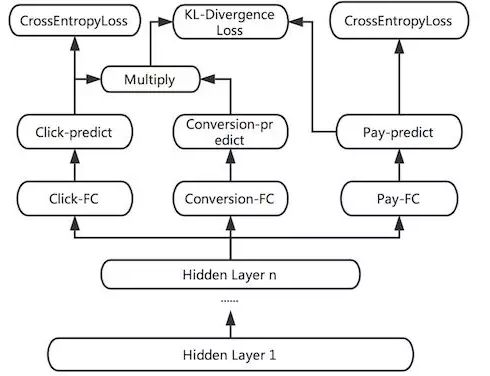
Figure 8 KL-divergence Bound
After the above work, the Multi-tast DNN model has been more stable than the XGBoost model. At present, the “Guess You Like†scene on the US group home page has been fully launched, and the click rate has been improved online:
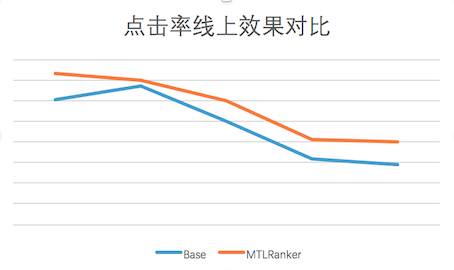
Figure 9 Online CTR effect and baseline comparison chart
The online CTR relative value increase is shown in the following table:
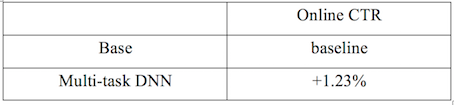
Figure 10 Online CTR effect relative value increase
In addition to the improvement of online effects, the Multi-task training method also improves the scalability of the DNN model. The model training can consider multiple business objectives at the same time, so that we can join the business constraints.
More exploration
After the Multi-task DNN model was launched, in order to further improve the effect, we took advantage of the flexibility of the DNN network structure and made various optimization attempts. The following is a detailed introduction to the exploration of NFM and user interest vectors.
NFM
In order to introduce the Low-order feature combination, we have tried to join NFM on the basis of Multi-task DNN. The discrete features of each domain first learn the corresponding vector expression through the Embedding layer. As an input of NFM, NFM performs 2-order feature combination on each dimension corresponding to the input vector by Bi-Interaction Pooling, and finally outputs a follow-up input. A vector with the same dimensions. We spliced ​​the vector learned by NFM with the hidden layer of DNN as a sample expression for subsequent learning.
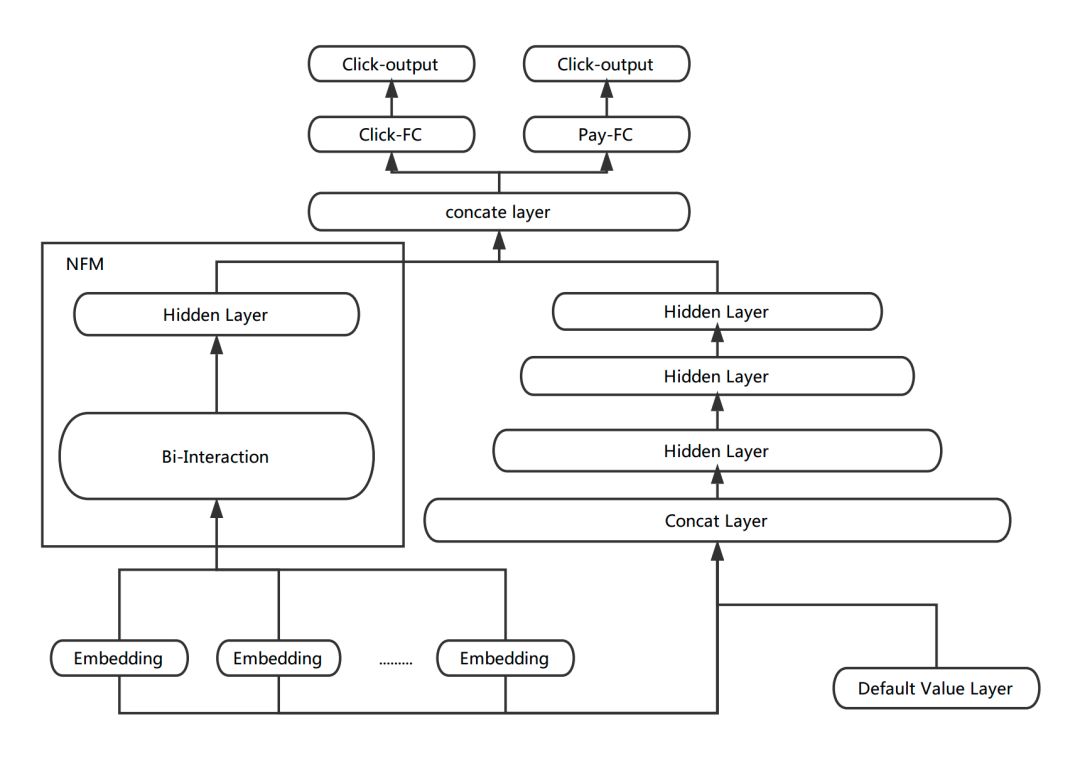
Figure 11 NFM + DNN
The output of the NFM is in the form of a vector, which is convenient for fusion with the hidden layer of the DNN. Moreover, from the research process, it is found that NFM can speed up the convergence of training, which is more conducive to the learning of the Embedding layer. Because the number of layers in the DNN part is large, in the BP phase of training, when the gradient is transmitted to the bottom layer of the Embedding layer, the gradient disappears easily. However, the number of layers of NFM is shallower than that of DNN, which is beneficial to the gradient. Thereby speeding up the learning of the Embedding layer.
After offline research, after joining NFM, although the convergence rate of training accelerated, AUC did not improve significantly. The reason for the analysis is that the features of the current part of the NFM model are still limited, which limits the learning effect. Subsequent attempts will be made to add more feature domains to provide enough information to help NFM learn useful expressions and dig deep into the potential of NFM.
User interest vector
User interest as an important feature is usually reflected in the user's historical behavior. By introducing a sequence of user history behaviors, we have tried a number of ways to vectorize user interests.
The vectorized representation of Item: The item in the sequence of user behavior printed on the line exists in the form of ID, so it is first necessary to Embedding the Item to obtain its vectorized expression. Initially we tried to learn by randomly initializing the Item Embedding vector and updating its parameters during the training process. However, due to the sparsity of the Item ID, the above random initialization method is prone to overfitting. Later, using Mr. into the item Embedding vector, the vector was used for initialization, and the fine tuning method was used for training during the training.
Vectorized representation of user interest: In order to generate the user interest vector, we merge the Item vector in the user behavior sequence including Average Pooling, Max Pooling and Weighted Pooling. Weighted Pooling refers to the implementation of DIN. First, the user's behavior sequence is obtained. Through a layer of nonlinear network (Attention Net), each behavior item is learned for the current Align Vector, according to the weight of the learning. Weighted Pooling of the behavior sequence, and finally generate the user's interest vector. The calculation process is as follows:
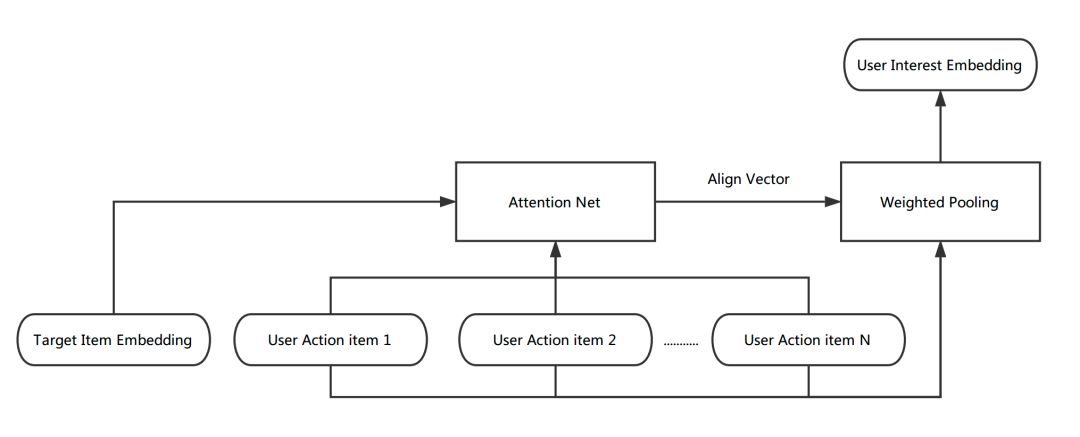
Figure 12 Weighted Pooling
Through offline AUC comparison, the effect of Average Pooling is optimal for the current training data. The effect is compared as shown below:
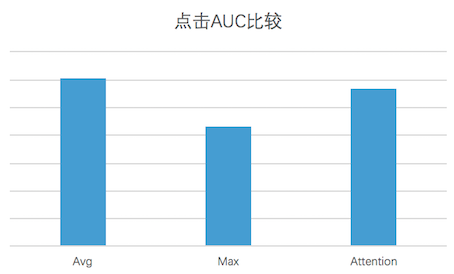
Figure 13 Comparison of different Pooling methods by clicking AUC
The above is our optimization experience and attempt in model structure. Below we will introduce the framework performance optimization work to improve the efficiency of model training.
Training efficiency optimization
After extensive research and selection of open source frameworks, we chose PS-Lite as the training framework for the DNN model. PS-Lite is a DMLC open source Parameter Server implementation, which mainly includes Server and Worker roles. The Server is responsible for storing and updating model parameters. The Worker is responsible for reading training data, building network structures, and performing gradient calculations. Compared to other open source frameworks, the significant advantages are:
PS framework: PS-Lite design can make better use of feature sparseness, suitable for recommending such scenes with a large number of discrete features.
Reasonable packaging: communication framework and algorithm decoupling, API is powerful and clear, and integration is convenient.
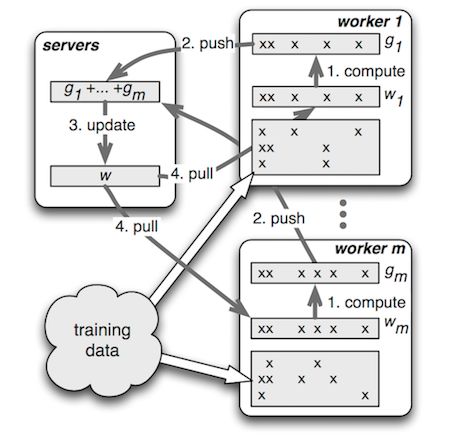
Figure 14 Parameter Server
During the development process, we also encountered and solved some performance optimization problems:
In order to save the worker's memory, usually not all the data is stored in the memory, but the Batch is pre-fetch data from the hard disk, but there are a lot of data parsing process in this process, and some metadata is repeatedly calculated (a large number of The key sorting is heavy, etc.), and the cumulative is also a considerable consumption. In response to this problem, we modified the way the data was read, serialized the calculated metadata to the hard disk, and pre-fetched the data into the corresponding data structure in advance through multi-threading, avoiding wasting a lot of waste here. Time to repeat calculations.
During the training process, the computing efficiency of the worker is affected by the real-time load and hardware conditions of the host. The execution progress between different workers may be different (as shown in the figure below, for the experimental test data, most workers will complete one in 700 seconds. Round training, while the slowest worker takes 900 seconds). Usually, after training an Epoch, it is necessary to perform a process such as Checkpoint of the model and evaluation index calculation, so the slowest node will slow down the entire training process. Considering that the execution efficiency of the Worker is roughly obeying the Gaussian distribution, only a small number of Workers are extremely inefficient, so we added an interrupt mechanism in the training process: when most of the machines have executed the current Epoch, the rest The Worker interrupts and sacrifices a small amount of training data on the Worker to prevent the training process from blocking for a long time. The interrupted Worker will continue training from the interrupted Batch at the beginning of the next Epoch, ensuring that the slow node can also utilize all the training data.
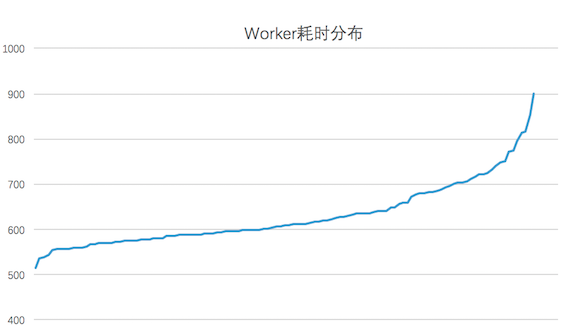
Figure 15 Worker time-consuming distribution
Summary and outlook
After the deep learning model reaches the recommended scenario, the business indicators have been significantly improved. In the future, we will deepen our understanding of the business scenarios and make further optimization attempts.
On the business side, we will try to abstract more business rules and add them to the model in the way we learn the goals. Business rules are generally proposed when we solve business problems in the short term, but the way to solve the problem is generally not smooth enough, and the rules will not adapt to changes in the scene. Through the Multi-task method, the business Bias is abstracted into a learning goal, and the learning of the model is guided during the training process, so that the business problem can be solved through the elegant model.
In terms of features, we will continue to conduct in-depth research on the mining and utilization of features. Different from other recommended scenarios, for O2O services, the role of the Context feature is very significant. Time, location, weather and other factors will affect the user's decision. In the future, we will continue to try to mine a variety of Context features, and use feature engineering or models to combine features to optimize the expression of the sample.
In terms of models, we will continue to explore the network structure, try new model features, and adapt to the characteristics of the scene. The successful experience of academia and industry is very valuable and provides us with new ideas and methods. However, due to the different business problems and the accumulated data of the scene, it is necessary to adapt the scene to achieve the business objectives. Upgrade.
Led Floor Panels,Led Dance Floor Panel,48W Led Light Panel,Floor White Uplight Panel Led
Kindwin Technology (H.K.) Limited , https://www.ktlleds.com