How trouble can you write a web page? In most companies, this work is divided into three steps:
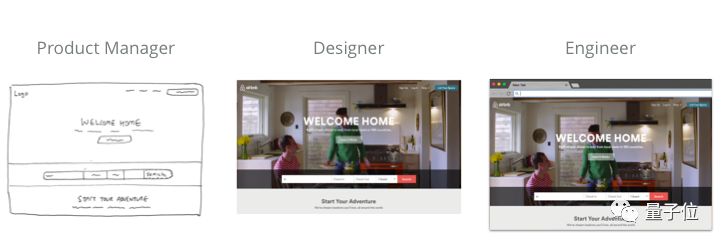
1. After the product manager completes the user research task, it lists a series of technical requirements;
2. Designers design low-fidelity prototypes based on these requirements, gradually modifying the high-fidelity prototypes and UI design drawings;
3. Engineers implement these designs as code, which eventually becomes the product used by the user.
With so many links, any problems in any place will lengthen the development cycle. Therefore, many companies, such as Airbnb, have begun to use machine learning to improve the efficiency of this process.
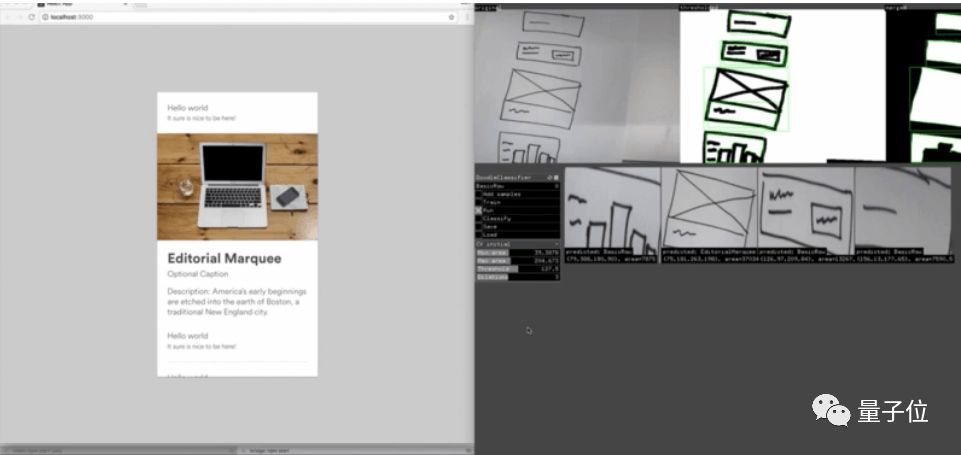
â–³ Airbnb internal AI tool, one step from drawing to code
It looks great, but Airbnb has not disclosed the details of the end-to-end training in the model, and the contribution of hand-designed image features to the model. This is a patent of the company's unique closed source solution and may not be disclosed.
Fortunately, a programmer named Ashwin Kumar has created an open source version that makes the job of the developer/designer easier.
The following is translated from his blog:
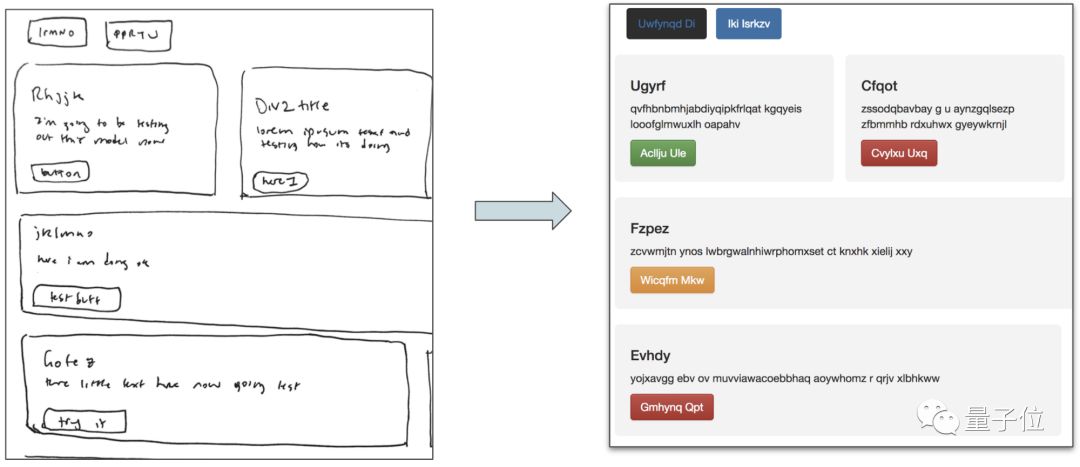
Ideally, this model can quickly generate a usable HTML website based on a simple hand-drawn prototype of the website design:
â–³ SketchCode model uses hand-drawn wireframes to generate HTML sites
In fact, the above example is a real website generated on the test set using the trained model. The code is available at https://github.com/ashnkumar/sketch-code.
Inspiration from image annotation
The current problem to be solved belongs to a broader task called program synthesis, which automatically generates work source code. Although many program synthesis studies generate code through natural language specifications or execution tracking methods, in the current task, I will make full use of the source image, that is, the given hand-drawn wireframe to work.
There is a very popular area of ​​research in machine learning, called image captioning. The goal is to build a model that connects images and text together, particularly for generating source image content.
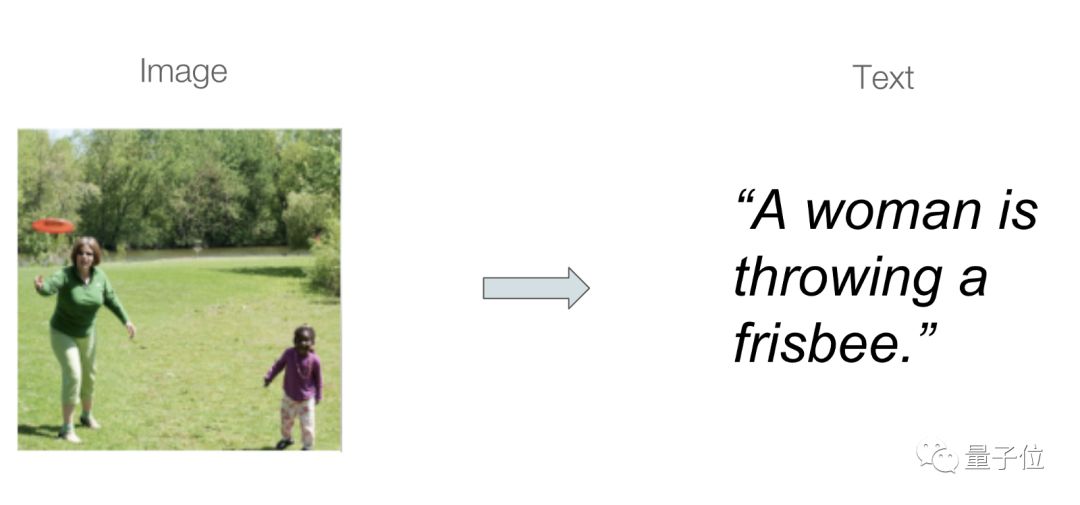
â–³ The image annotation model generates a text description of the source image
I got inspiration from a pix2code paper and another related project that applied this method. I decided to implement my task in terms of image annotation, using the drawn website wireframe as input image, and using the corresponding HTML code as Its output content.
Note: The two reference projects mentioned in the previous paragraph are pix2code papers: https://arxiv.org/abs/1705.07962floydhub Tutorial: https://blog.floydhub.com/turning-design-mockups-into-code-with -deep-learning/?source=techstories.org
Get the right data set
After determining the image annotation method, the ideal training data set will contain thousands of pairs of hand-drawn wireframes and corresponding HTML output codes. However, there is currently no relevant data set I want. I have to create data sets for this task.
Initially, I tried the open source data set given in the pix2code paper, which consists of a screenshot of 1,750 integrated production sites and their corresponding source code.
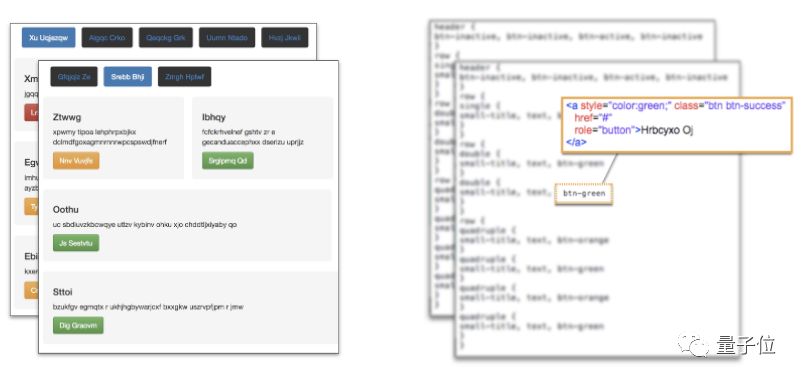
â–³ Pix2code dataset generated site images and source code
This is a good data set. There are several interesting places:
Each generated website in the data set contains several simple helper elements such as buttons, text boxes, and DIV objects. Although this means that this model is limited to having these few elements as its output, these elements can be modified and extended by selecting the generation network. This method should be easily generalized to the larger element vocabulary.
The source code for each sample consists of domain-specific language (DSL) tokens, which the author of the paper created for this task. Each token corresponds to a snippet of HTML and CSS and joins the compiler to convert the DSL into running HTML code.
Color website image change hand drawing
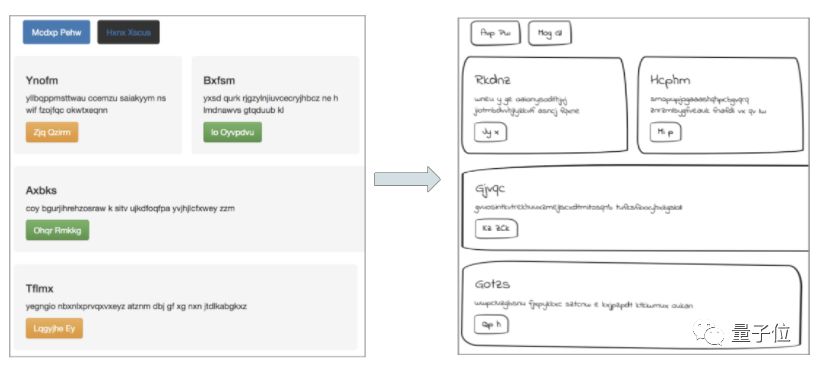
In order to modify my task data set, I want to make the website image look like hand drawn. I tried to modify each image using tools such as OpenCV library and PIL library in Python, including grayscale conversion and contour detection.
In the end, I decided to directly modify the original site's CSS stylesheet by doing the following:
1. Change the border radius of the elements on the page to smooth the edges of buttons and DIV objects;
2. Simulate the sketch to adjust the thickness of the border and add shadows;
3. Change the original font to a handwritten font;
A step has also been added to the final implementation flow to achieve image enhancement by adding tilt, movement, and rotation to simulate changes in the actual sketching.
Using image annotation model architecture
Now that I have processed the data set, the next step is to build the model.
I took advantage of the model architecture used in image annotation, which consists of three main parts:
1. A computer vision model using a convolutional neural network (CNN) to extract image features from source images;
2. A language model containing a gating unit GRU that encodes the source code token sequence;
3. A decoder model, also belonging to the GRU unit, takes the output of the first two steps as input and predicts the next token in the sequence.
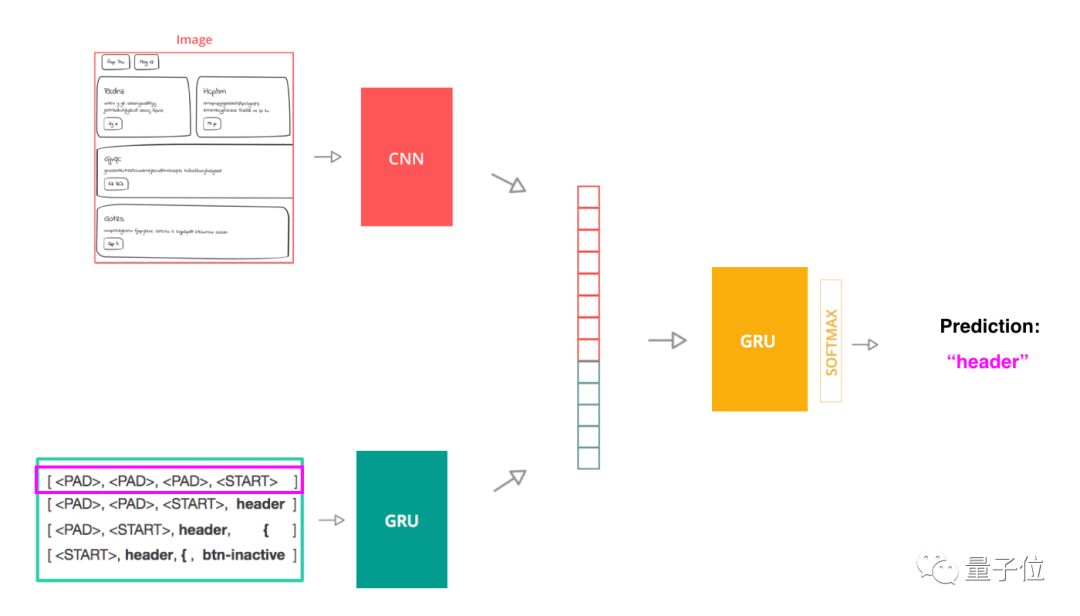
Train the model with the token sequence as input
In order to train the model, I split the source code into token sequences. The input to the model is a single partial sequence and its source image, whose label is the next token in the text. The model uses the cross-entropy function as a loss function to compare the model's next prediction token with the actual next token.
The reasoning is slightly different when the model is generating code from scratch. The image is still processed through the CNN network, but text processing starts with only one startup sequence. In each step, the next prediction token output by the model pair sequence is added to the current input sequence and sent to the model as a new input sequence; this operation is repeated until the model's prediction token is, or the process The predefined number of tokens per text is reached.
When the model generates a set of prediction tokens, the compiler converts the DSL tokens into HTML code that can be run in any browser.
Using the BLEU score to evaluate the model
I decided to use the BLEU score to evaluate the model. This is a common metric used in machine translation tasks to measure the degree of similarity between machine-generated text and human-generated content given the same inputs.
In fact, the BLEU compares the N-grams of the generated text and the reference text to create a modified and accurate version. It works well for this project because it affects the actual elements in the generated HTML code and their interrelationships.
Best of all, I can also compare current actual BLEU scores by checking the generated websites.
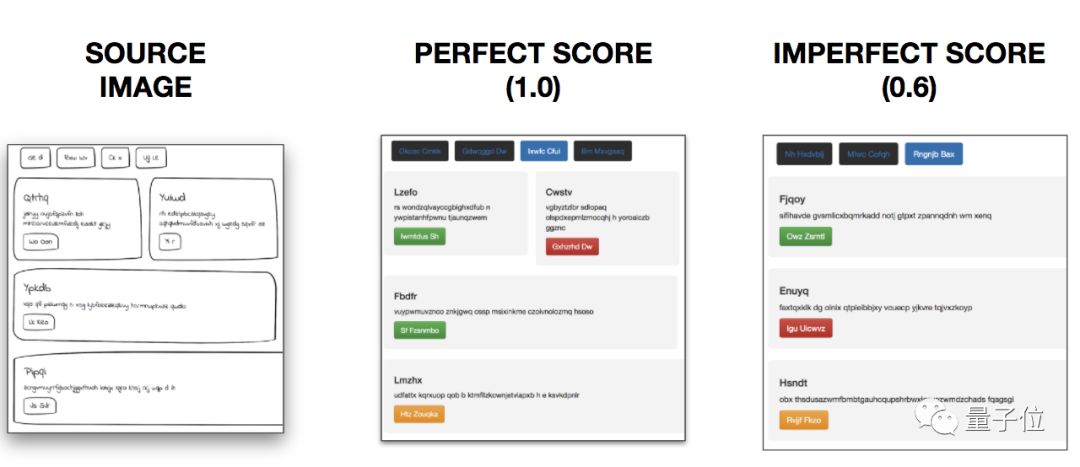
â–³ Observe the BLEU score
When the BLEU score is 1.0, it indicates that the model can set the appropriate elements in the correct position after a given source image, and the lower BLEU score indicates that the model predicts the wrong elements or places them in relatively inappropriate positions. Our final model has a BLEU score of 0.76 on the evaluation data set.
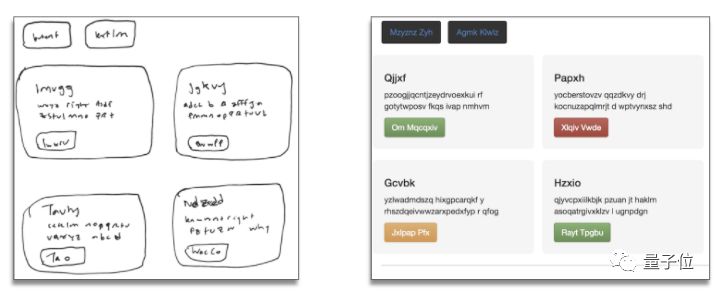
Benefits: Custom web style
Later, I also thought that because the model only generates the current page's frame, that is, the text of the token, so I can add a custom CSS layer in the compilation process, and immediately get different styles of generating sites.
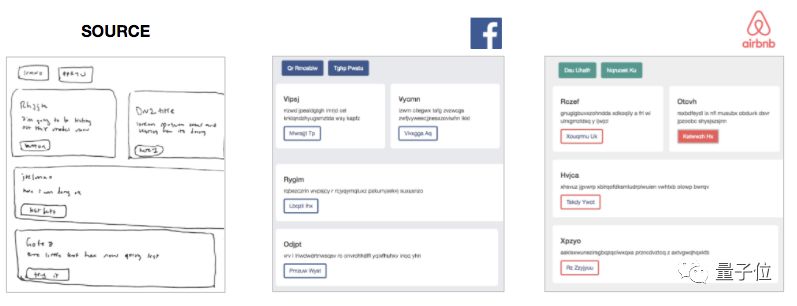
â–³ A hand-drawing generates multiple styles of web pages
Dividing the style customization and model generation processes brings many benefits when using the model:
1. If you want to apply SketchCode model to your company's products, front-end engineers can use the model directly, just change a CSS file to match the company's web design style;
2. The built-in extensibility of the model, that is, through a single source image, the model can quickly compile a variety of different pre-defined styles, so the user can imagine a variety of possible web site styles, and browse these generated web pages in the browser .
Summary and outlook
Inspired by image annotation research, the SketchCode model can transform hand-drawn website wireframes into usable HTML sites in seconds.
However, there are still some problems with this model, which is also my next possible direction of work:
1. Since this model uses only 16 elements for training, it cannot predict tokens other than these data. The next step may be to use more elements to generate more sample websites, including website images, drop-down menus, and forms. See Launcher Components (https://getbootstrap.com/docs/4.0/components/buttons/). To get ideas;
2. There are many changes in the actual website construction. Creating a training set that better reflects this change is a good way to improve the build effect, which can be improved by getting more HTML/CSS code for your site and screenshots of the content;
3. Hand-painted drawings also have many changes that cannot be captured by CSS modification techniques. A good way to solve this problem is to use Generating Fight Network GAN to create a more realistic rendering site image.
DC Permanent Magnet Gear Motor
Dc Motor,24V Dc Gear Motor,Electric Gear Motor,Dc Permanent Magnet Gear Motor
NingBo BeiLun HengFeng Electromotor Manufacture Co.,Ltd. , https://www.hengfengmotor.com