Since the development of machine learning, we have seen many AI models that can draw pictures and compose music through a large amount of data. But now a "magic" website can generate unexpected images from your text. Things have to start with a paper more than half a year ago.
In a paper published in January this year, interns from Microsoft Research trained a machine learning algorithm called AttnGAN. This is a variant of GAN that can generate images based on written text, and the image quality is three times that of the previous technology.
This technology can generate any image, from ordinary pastoral scenery to abstract scenes, each image can be described in detail.
Introduction
Recently, many methods of text generation images are based on Generative Adversarial Networks (GAN). The common method is to write a complete text description into the entire sentence vector as a condition for image generation. Although it has been able to generate good-quality images, GAN cannot generate higher-quality images due to the lack of fine-tuning information at the word level of sentence vectors. This problem is more serious when generating complex scenes.
In order to solve this problem, the author proposes the Attention Generative Adversarial Network (AttnGAN), which uses an attention-driven, multi-stage method to fine-tune the problem of text-generated images. The overall structure of AttnGAN is shown in the figure:
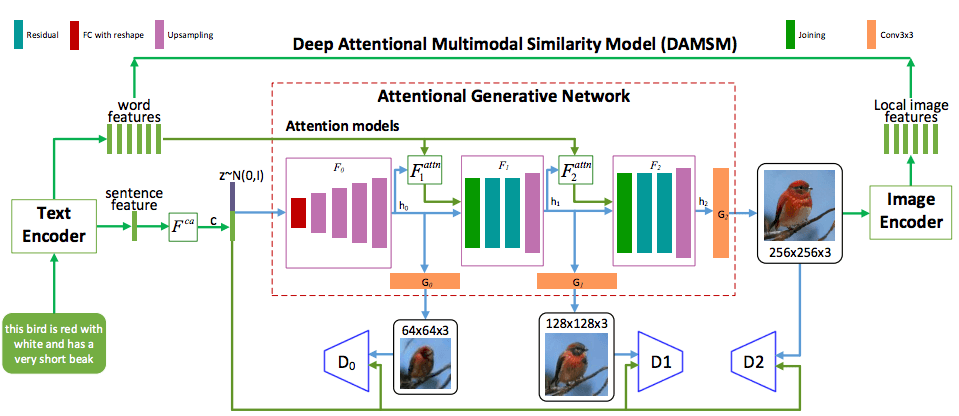
The model has two innovative elements. The first is the attention generation network, where the attention mechanism is to observe the most relevant text in the area, and the generator draws different parts of the image.

More specifically, in addition to encoding the natural language description into the global sentence vector, each word in the sentence also has a corresponding vector. In the first stage, the generation network uses the global sentence vector to generate a low-resolution image. Then, it uses the image vector of each region to query the word vector through the attention layer to form a word-context vector. After that, it will combine the regional image vector with the corresponding word-context vector to form a multi-modal context vector. This can generate more detailed high-resolution images at various stages.
Another important part of this structure is the Deep Attention Multimodal Similarity Model (DAMSM). Due to the attention mechanism, DAMSM can calculate the similarity between the generated image and the sentence. Therefore, DAMSM provides an additional adjustment loss function for the training generator.
Model test
Same as the previous method, the method proposed in this paper is also tested on the CUB and COCO data sets. The final training results are as follows:

The first picture of each scene is the first stage (G0) of AttnGAN, which only depicts the original outline of the scene, and the image resolution is very low. Based on the word vector, the next two stages (G1 and G2) learn to correct the previous results.

Generated results on the CUB data set

The results generated by the model trained on the COCO dataset, the description in the figure is almost impossible to appear in reality
Strange direction
In general, AttnGAN's performance is still good. However, some foreign researchers have gradually found new ways to play. Researcher Cristóbal Valenzuela built a website based on the paper. Users can try AttnGAN, but the difference is that the training data is replaced with a larger data set. Machine learning enthusiast Janelle Shane wrote in a blog: "When this algorithm is trained on another larger and more diverse data set, the generated images are difficult to match the text description (and become very strange). "For example, in the following example, with the same sentence, the picture generated with the original model looks like this:

However, after changing the training data set:

what is this? Because it has been trained on a larger data set, when GAN wants to draw the content I require, it has to search for more images and the problems become more extensive. There are not only restrictions on the generation of birds, but also bugs in the generation of portraits, as shown in the figure below:

This behaves badly, and it is impossible to tell where the face is. There are many other similar works, which are completely surrealist works.



Janelle Shane said: "This demo is very interesting. It also reflects how the current advanced image recognition algorithms understand images and text. How do they understand "dogs" or "humans"? In 2D images, the people that the algorithm sees point to The front and the sides are completely different."
For this result, Tao Xu, the author of the AttnGAN paper, also responded. Xu is currently a graduate student at Lehigh University in the United States. She believes that this is an important improvement to the results of the thesis:
"With the rapid development of deep learning, computer vision systems are very powerful. For example, they can diagnose diseases from medical images and locate pedestrians and cars in autonomous driving systems. However, we still cannot think that these systems fully understand what they see. Because if machines really have wisdom, they will not only recognize images, but can generate images.
Our AttnGAN combines the attention mechanism with the generative confrontation network, which greatly improves the performance of the text-generated image model. Since attention is a concept unique to humans, our AttnGAN can learn this "wisdom" and draw like humans, that is, pay attention to related words and related image areas.
Although AttnGAN performs better than previous text-to-image models, generating multiple "realistic style" objects is still a problem to be solved for the entire field. We hope to conduct more research in this direction in the future. "
Shenzhen Kate Technology Co., Ltd. , https://www.katevape.com