Artificial intelligence is a hot topic in today's hot industry. Deep learning is a hot topic, but for traditional IT practitioners, artificial intelligence technology is full of models, algorithms, vector vectors, and it is too difficult to understand. So the goal of this article is to enable IT practitioners to understand the characteristics of deep learning technology and hope that readers will benefit from it.
First, the artificial intelligence of the time and place andThe maturity of the industry depends on the struggle of the practitioners (people and people), but also the process of the environment and history (day and place).
The blowout of artificial intelligence technology is not a simple technological advancement, but the result of the joint efforts of software, hardware and data. Deep learning is the hottest branch of AI technology, and it is also limited by these three conditions.
The algorithms that AI software relies on have been around for many years. Neural networks are technologies proposed 50 years ago, and algorithms such as CNN/RNN are older than most readers. AI technology has been shelved because of the lack of hardware power and massive data. With the update of CPU, GPU, and FPGA hardware, the hardware computing power has been expanded by 10,000 times in decades, and the hardware computing power has been gradually liberated. With the speed reduction of hard drives and bandwidth, there weren't a few high-definition photos of all humans 20 years ago, and now the data volume of a single company can reach EB. Big data technology can only read and write structured logs. To read videos and pictures, you must use AI. Humans have been unable to stare at so many cameras.
We can only use AI technology from the heart to go to the altar to use it as a convenient tool. AI's technology is very deep in theory, mainly because the industry has just sprouted and has not been stratified. Just like IT engineers needed to master the skills 20 years ago, the children's hyphens don't need to pay attention.
Second, the relevance modelDeep learning has two steps. You must first train the generated model and then use the model to guess the current task.
For example, I used 1 million images to mark whether this is a cat or a dog. The AI ​​extracts the features of each segment in the image to generate a cat and dog recognition model. Then we will put the model on the interface to make a dog and dog detection program. Each time you give this program a photo, it will tell you how likely it is that the cat has a chance to be a dog.
This recognition model is the most critical part of the whole program, and it can be vaguely considered to be a recognition function of a sealed black box. In the past, we wrote the program to do if-then-else causal judgment, but the image features have no causal relationship and only look at the degree of relevance. The past work experience has become a new cognitive obstacle. It is better to use it as a black box. use.
Next, I put a screenshot of the experimental training and speculation experiment steps to explain two questions:
It is necessary to use the customer's field data for training to get the model. The training model is not a software outsourcing day, and it is difficult to directly commit to the model training results.
The process of training the model is cumbersome and time consuming, but it is not difficult to master. The work pressure is much smaller than the DBA online debugging SQL. IT engineers still have a place in the AI ​​era.
Third, hands-on experimentThis section is longer. If you are not interested in the experimental steps and results, but want to see my conclusions directly, you can skip this section.
This lab is an introductory training course offered by Nvidia - ImageClassificaTIon with DIGITS - Training a model.
Our experiment is very simple, using 6,000 images to train the AI ​​to recognize the numbers 0-9.
The training sample data is 6000 small pictures with numbers 0-9, of which 4500 are used for training and 1500 are for val training.
Experimental data preparation
The training picture is very small and very simple. The preview below is a bunch of numbers:
-- The picture below is a 01 sample picture --

The picture I made for testing is the official tutorial that provides a "2" with a red text on a white background.
-- The picture below is 02 test picture --

Production data set
First, we need to make a dataset for image recognition. The dataset file is placed in the "/data/train_small" directory. The image type is "Grayscale", the size is 28x28, the others are selected as defaults, and then the dataset "minidata" is selected. .
-- The figure below is the 03 initial data set --
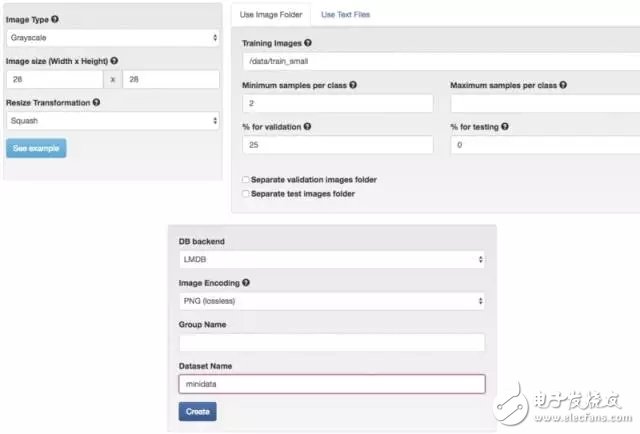
The following is the process of data set creation, because our files are very small, so the speed is very fast; if it is tens of millions of high-definition big pictures, the speed will be very slow, even to build a distributed system to spread IO to multiple machines on.
-- The figure below is the 04 initial data set --
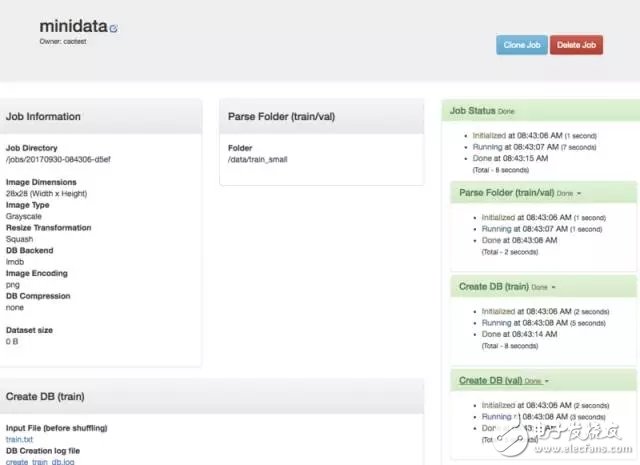
This is a column chart that creates a completed dataset with the mouse just resting on the second bar, showing 466 of the images currently marked "9".
-- The figure below is 05 Create completed data set --
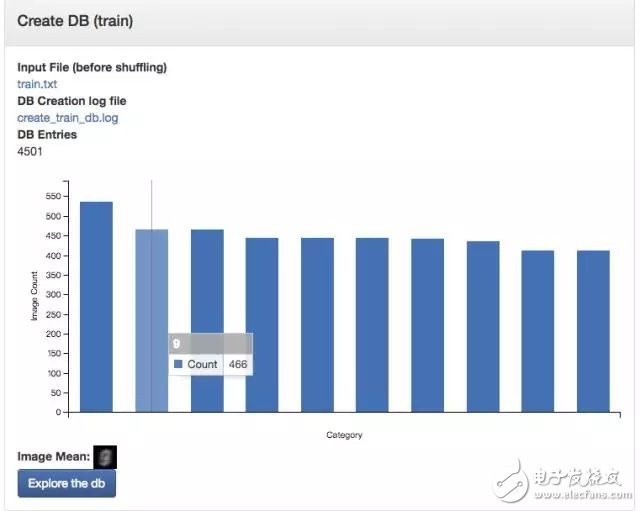
Start creating a model
With the dataset we can create the model. We choose to create an Image ClassificaTIon Model. The dataset is selected as the "minidata" created before. The training circle is lost 30 times. Other options are temporarily kept default.
-- The picture below is a new model of 06 --
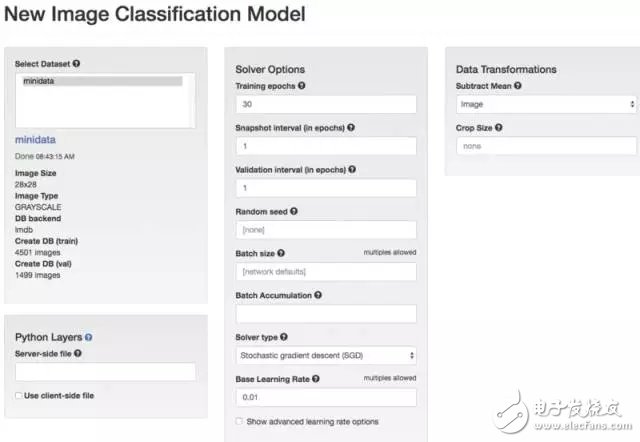
In the second half of the creation of the model is to choose the network configuration, we can choose LeNet, the model is named TestA.
-- The picture below is 07 Select LeNet --
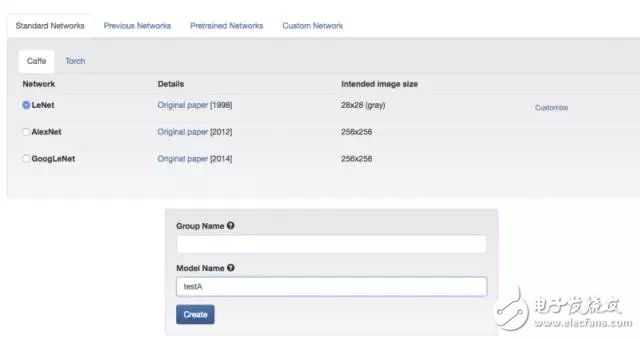
We didn't do the details of the demo, but the production environment may have to modify the configuration file frequently.
-- The picture below is 08 fine-tuning LeNet --
The next step is to generate the model. The speed of the simple task of the small data set is still very fast, and the verification accuracy is very high. But if it is a big task big model, it may take a few days.
-- The figure below is 09 to start generating models --
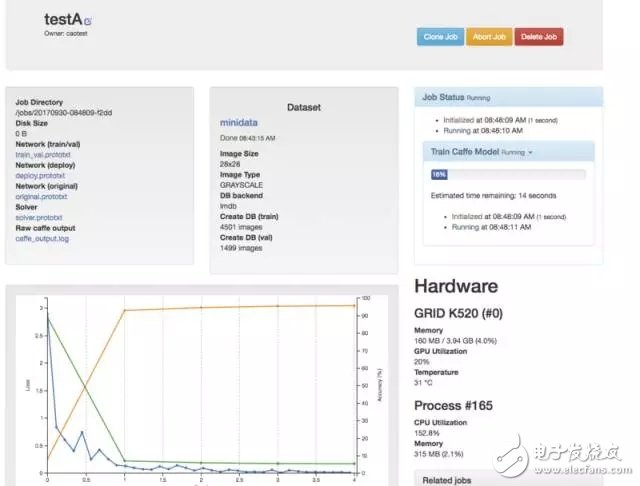
The model generation is complete. Let's take a look at the verification accuracy rate. If the production environment correct rate is too low, you may want to fine-tune the parameters of the model.
-- The picture below is the accuracy of 10 training--
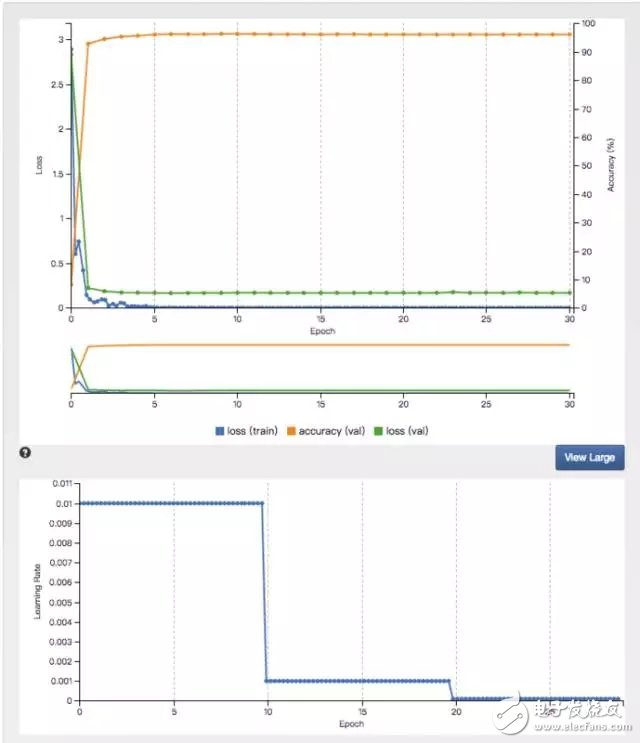
Debug model
Drag down on the model page to see the download model, test model and other buttons. We choose the test model and submit the "Red Letter 2 on White" for testing.
-- The figure below is the 11 test model --
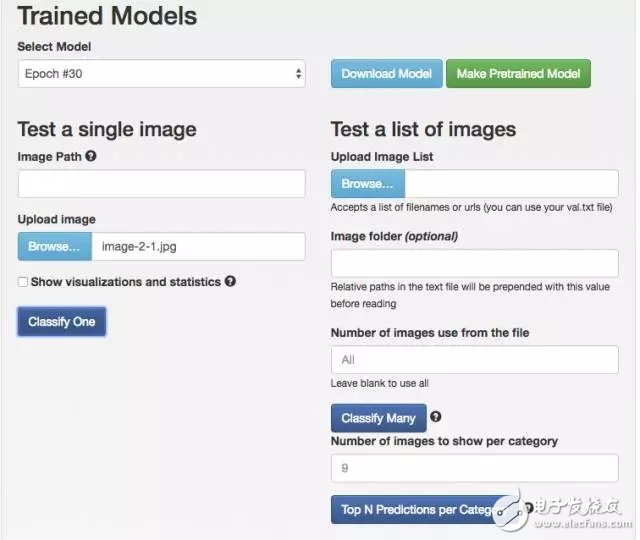
The default is to test Epoch #30, let's try it 10 times. Originally, I wanted to save the server electricity bill. As a result, only 20.3% of the chances were correctly identified.
-- The figure below is the result of 10 laps of the 12TestA model --
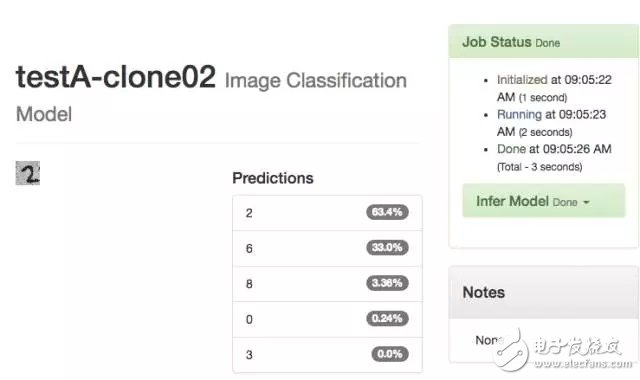
We increased the number of test cycles to 25 laps, and the accuracy of the results increased from 20.3% to 21.9%.
-- The figure below is the result of 25 laps of the 13TestA model --
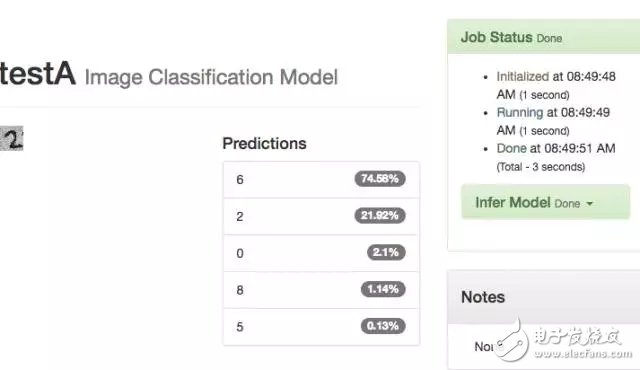
The upper limit of the entire model is 30 laps, and the correct recognition result is only 21.92%. When I got here, I didn't recognize it correctly because my modeling data was 28*28 black and white, and I didn't give the test image size and color.
-- The following figure is the result of 30 cycles of the 14TestA model --
Replace the model and continue debugging
On the TestA model, you can click the clone task, that is, make a model with the same configuration and run it again. This button is interesting. When we didn't pass the compiler, the retry 100,000 times is not passed. Why is the clone task a common panel? Button?
-- The picture below is a 15 clone model TestA --
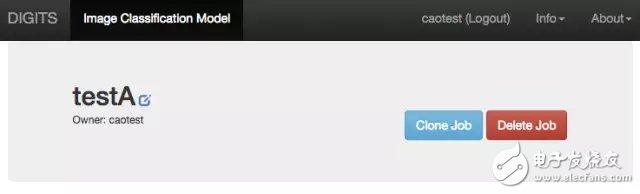
At this time, the fun thing happened. The "TestA-Clone" I made, the probability of identifying the number 2 is 94.81%.
-- The figure below is the result of 16 clone TestA --
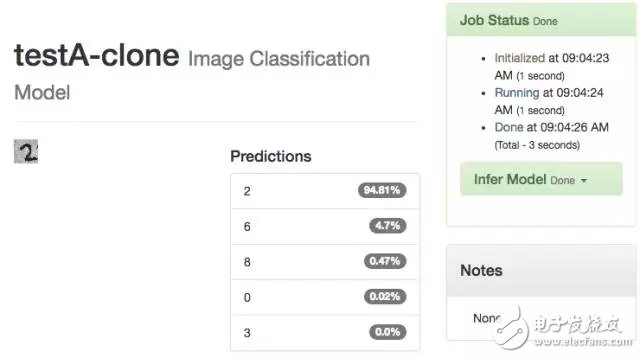
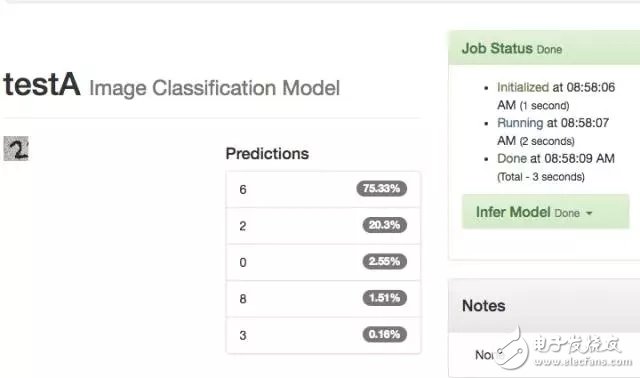
We cloned the old model again, and the probability of identifying the number 2 was 63.4%.
-- The figure below is 17 again to clone TestA results --
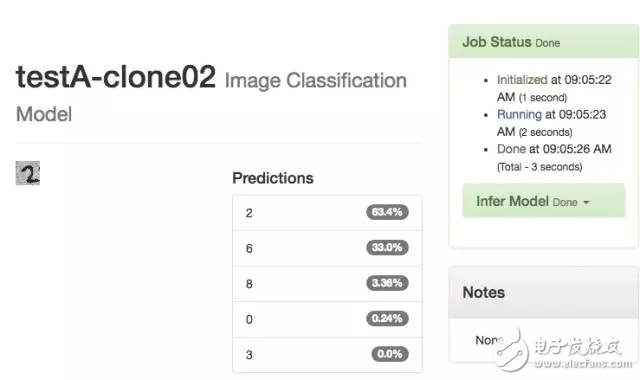
Create a new model TestB and let it train again on the basis of TestA.
-- The picture below is 18 new TestB --
TestB's training results are not as good as the original version of the model, the correct rate is 20.69%.
-- The picture below shows the training results of 19TestB --
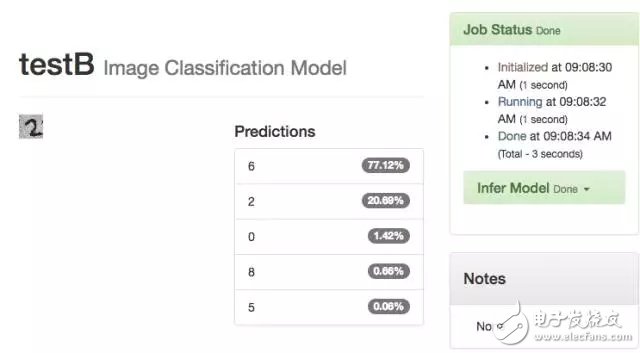
Not the worst, only worse, see my new training model TestC.
-- The picture below shows 20TestC training failure --
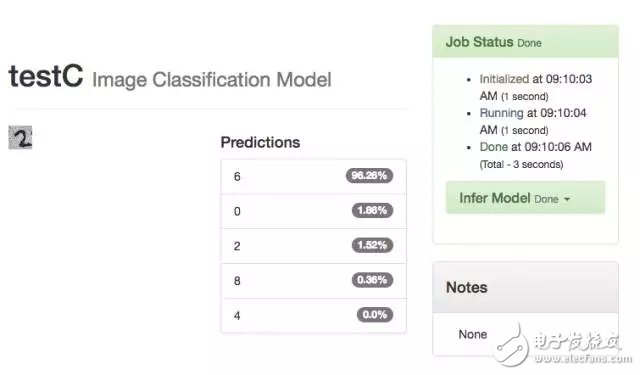
From this test, the best model is TestA-Clone, followed by Clone2.
-- The figure below is a summary of 21 model results --
But does this find a suitable model? I also handwritten a number 2, and specially selected the white background 28*28 on the black background. As a result, none of the models were identified accurately, and all the recognition failed.
-- The figure below is 22. New map recognition failed --
In this experiment, the model with a correct rate of 94.81% was an unexpected surprise, and the failure of that model to measure other images was unexpected. Because the initial sample of this experiment is only a few thousand, if the number of samples is enough, the possibility of overfitting (that is, the noise feature is included in the model) is less; I use all the default debugging options, add other feature debugging The model may reduce the chance of under-fitting (the main feature is not extracted); I did not explicitly define the usage scenario for the model, ie there is no clear training data, test files and production files are the same.
We see the model with the exact same configuration. The recognition result of the same picture is very different only because the time of clicking the model is different. It is emphasized again that this is not a causal judgment but a correlation calculation. The conclusion of the experiment is the same as my claim above. The model needs actual training with actual combat data, and we can only predict but not predict the model. I am doing this experiment to explain to everyone that AI model training is not software outsourcing, and it is not the price that can be used to plan the daily prediction effect.
An AI technology vendor simply sells off-the-shelf models, such as face recognition models, OCR recognition models, and more. However, if the customer has customized requirements, such as identifying acne on the face and identifying whether the left-hander is signed, then it is necessary to first define the technical scene and then prepare the data for a big job. As for the time when the model is trained for 1 day or 1 month, the AI ​​model training is like a material test. It may take half a year or so to find the target.
Fifth, the new work of IT engineersI mentioned two points in the previous article. The second point is that it is not difficult to train the model. IT engineers can easily learn to train the model, and then we can continue to expand the scope of the industry and share a cup of heat in the big wave of AI. Oh.
First of all, technology is not a threshold. Let's take an example that IT engineers can understand: an Oracle DBA has not read the database source code, has not touched new business scenarios, and even lacks theoretical knowledge can only do common operations; now this project can Slowly go online, let him debug SQL offline, and get the best performance point log save to complete. When doing AI model debugging, knowing the principle of understanding the algorithm will make the work more purposeful, but more purposeful can only guarantee the proximity and can not guarantee the hit target.
According to the above experiment, we can see that the following work is required:
According to the customer's request, the demand for raw data is raised. Here is the brain of the business direction, for example, to find out who is prone to obesity, naturally can think of everyone's diet and exercise habits, but professional doctors will tell you to transfer data such as transaminase cholesterol.
Raw data needs to be cleaned and labeled, and samples that do not find correlation are not unlabeled samples. The 6000 images in the previous experiment can all be labeled with 0-9 digits. We tested the model to find the relevance of the "2" group of images. The work of cleaning, sorting and labeling data may be automatic or manual. Automatically, we write scripts or run big data. Manually is to raise the demand and then recruit 1500 aunts to frame the yellow map, but the engineer will box. The whole process of the process. There is also a tricky way. The model of the friend is too expensive or even sold. It is to directly use the public cloud API interface of the friend, or buy the log of the big customer of the friend, so that the friend can help you complete the data screening.
In the above test, it is only a picture classification data set. There are already many adjustable options. The production environment not only has pictures, but also sound, text, motion characteristics and other data sets. Whether the data set is reasonable or not, you need to rebuild the data set. Multiple commissioning and long-term observation.
It takes only a minute to generate the model without adjusting the parameters in the experiment, but the model generation parameters of the production environment should be adjusted frequently, and the time to generate a model may be hours or even days.
To verify the accuracy of the results, if it is a flexible requirement, you can visualize several test results and put the model online. However, if it is a rigid business, it may organize more than 100,000 samples for test verification. By the way, the hardware used to train the model is not necessarily suitable for verifying and running the production environment. If it is a high-stress test, it may be replaced by hardware deployment.
The model also has daily maintenance, and may be updated regularly as the dataset is updated. It may also be found that the model has a fatal misjudgment that threatens the business, which requires timely processing.
Sixth, the attached small point of viewWhen it comes to the end, I will attach some personal opinions, and I will only write the arguments and do not write the argumentation process:
It is difficult to set up and use the AI ​​environment now, but the software will improve and solve this problem. Three years ago, the cloud computing platform was difficult to deploy and maintain. Now it is a cloud platform solution with one-click deployment and UI maintenance.
Deep learning This technology field is too much data and computing power. The human brain is not as stupid as AI. It may be that new technologies will appear in the future to replace the deep learning position in the AI ​​field.
Because of the need for data and computing power, it is more difficult to engage in an AI company than other startups; now the well-known AI startups are immersed in a single field for more than three years, allowing users to provide data only to a single typical model. It is not easy for giant companies to engage in AI. Even if they dig into a human AI project, they will take time to start coldly. Cleaning data not only consumes physical effort but also consumes time.
The calculation process of deep learning is not controlled, and the calculation results need to be verified by humans, so it cannot be used as evidence of practice. When the AI ​​discovers the suspect, the police will take immediate action, but its creators cannot describe how the AI ​​will play Go next. A baby can pee out of the world map, someone can easily touch the password of the bank card, AI will tell you that the stock market 99.99% will skyrocket, but these can not be used as evidence of independent responsibility.
Engaging in AI requires a lot of data. China has a special advantage for the United States. There are many people who can do data annotation and the price is cheap. However, in the practice of model practice, China's labor cost is too low and it limits the AI ​​to commercial use.
Don't panic that AI will destroy human beings. The AI ​​that threatens humanity is definitely a flawed AI, but humans have also chosen such defective leaders as Hitler. Don't preach that AI will make human beings unemployed in social turmoil. Let's talk about the horoscope fortune. Why don't I worry about losing my job?
In some cases, the accuracy of AI seems to be very low. For example, if two people can understand 80% of the words, it is not bad. AI only understands that 85% of the words have become more human. You see that my downsizing does not affect your reading.
The SCSI interface is a general interface, which can connect the host adapter and eight SCSI peripheral controllers on the SCSI bus. The peripheral devices can include disk, tape, CD-ROM, rewritable optical disk drive, printer, scanner and communication equipment, etc.
â— SCSI is a multi task interface with bus arbitration function. Multiple peripherals attached to a SCSI bus can work at the same time. Devices on the SCSI share the bus equally.
â— the SCSI interface can transmit data synchronously or asynchronously, the synchronous transmission rate can reach 10MB / s, and the asynchronous transmission rate can reach 1.5mb/s.
â— when the SCSI interface is connected to an external device, its connecting cable can be as long as 6m.
Small computer system interface (SCSI) is an independent processor standard used for system level interface between computer and intelligent devices (hard disk, floppy drive, optical drive, printer, scanner, etc.). SCSI is an intelligent universal interface standard
Plastic SCSI Section
ShenZhen Antenk Electronics Co,Ltd , https://www.pcbsocket.com